Como trocar mensagens entre microsserviços com Apache Kafka e Golang


Embora os microsserviços tenham conseguido revolucionar o cenário de desenvolvimento, dar maior agilidade aos desenvolvedores e reduzir dependências como bancos de dados compartilhados, as diferentes aplicações que fazem parte deles precisam se integrar de forma mais coesa.
Diante desse problema, foram criadas diversas alternativas que podem ser categorizadas de acordo com o método, seja ele síncrono ou assíncrono. A primeira utiliza APIs para troca e compartilhamento de dados entre usuários; o segundo replica os dados para uma fila intermediária, assim como faz o Apache Kafka.
Requisitos para este tutorial:
- Última versão do Golang.
- Docker.
Aqui vamos implementar um trocador de mensagens para comunicar dois microsserviços com bancos de dados individuais. Nosso microsserviço 1 irá gerar uma mensagem que salvará em um banco de dados fictício e enviará a mesma para o trocador de mensagens Kafka, enquanto nosso microsserviço 2 aguardará uma mensagem para armazenar em seu próprio banco de dados fictício.
Como funciona o Apache Kafka?
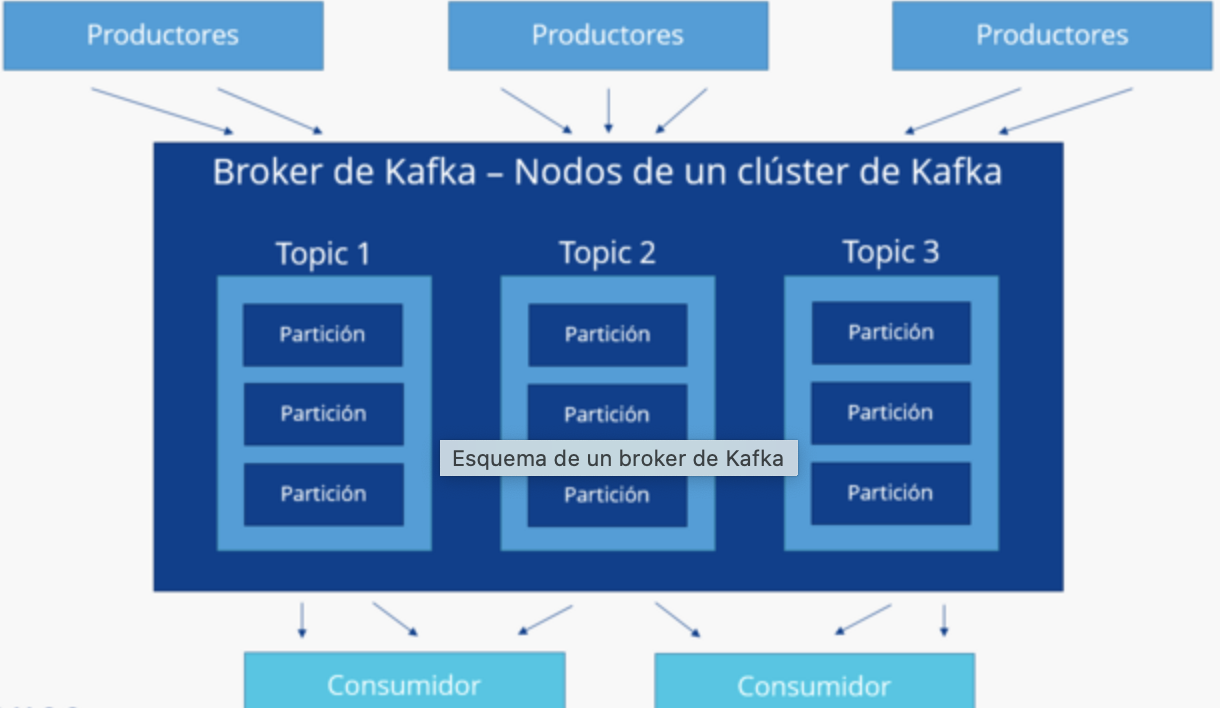
Para entender como o Apache Kafka funciona, é necessário considerar algumas noções básicas. Primeiro, temos os produtores, que se referem aos aplicativos que gravam dados nos clusters Kafka. Por outro lado, existem os consumidores, ou seja, as aplicações que leem esses dados nos clusters.
As duas partes, produtores e consumidores, quando processam fluxos de dados, acessam um componente central comum: Kafka Streams, uma biblioteca Java. A transmissão de mensagens que se aplica no processo se dá por meio de uma escrita transacional que permite uma exactly-one delivery, ou seja, as mensagens são transmitidas uma única vez sem duplicação.
Por que Golang?
Golang, também conhecida como Go Programming Language, é uma das mais recentes linguagens de programação Open Source e, de fato, é a que mais cresce atualmente, ganhando cada vez mais popularidade entre os desenvolvedores. Foi desenvolvido em 2007 por Ken Thompson e Rob Pike, programadores do Google que já construíram uma carreira renomada criando as linguagens de programação B e Limbo.
No início, Golang era apenas um padrão de codificação interno para melhorar a simultaneidade ou tarefas simultâneas de outras linguagens. No entanto, ao longo do tempo, mostrou um grande potencial que permitiu que se tornasse uma das linguagens de programação favoritas do mundo.
As principais características que destacam o Golang são sua escalabilidade, sua eficiência e sua produtividade, entre outras. Por um lado, sua escalabilidade permite aproveitar múltiplos núcleos de hardware de forma escalável, ao contrário das linguagens de programação anteriores que não podiam aproveitar múltiplos núcleos para maximizar o desempenho porque foram criados quando os computadores tinham apenas um. Além disso, vários programadores podem trabalhar no mesmo projeto com risco mínimo de erros graves e modificações indesejadas.
Por outro lado, a estrutura de Golang reduz as chances de processos concorrentes ficarem fora de sincronia. Assim, diferentes modelos de concorrência podem ser usados dependendo do objetivo e tarefas simultâneas podem ser realizadas em paralelo. Assim, torna-se uma linguagem multiparadigma que suporta programação estruturada, funcional e orientada a objetos. Além de tudo, Golang possui ferramentas próprias para otimizar o uso de memória, como um coletor de lixo.
Por fim, vale destacar a acessibilidade de Golang. À primeira vista já é fácil de entender, manter e modificar, pois possui uma sintaxe bem simples e foi pensado para tornar o trabalho de programação mais eficiente. Funciona perfeitamente em ambientes de nuvem e, para maior confiança, possui travas de segurança contra erros e execução suspeita.
Passo 1: Criação do proyecto

Nosso projeto base será uma pasta pai chamada Kafka_tutorial. Nele criaremos 3 pastas: db, ms-consumer e ms-producer.
Passo 2: Gerar um arquivo docker-compose.yml na raiz do nosso projeto
Esta será o Docker compose que precisaremos para nosso tutorial. Nele incluímos todas as nossas dependências, serviços, variáveis de ambiente e imagens:

Passo 3: Instalação das bibliotecas e dependências necessárias requeridas para que nosso tutorial funcione perfeitamente
Vamos abrir um terminal na raiz do nosso projeto e digitar o seguinte:

Agora, bem na raiz do nosso projeto, vamos escrever:

Iremos ao nosso arquivo go.mod e clicaremos em Run go mod tidy:

Agora nosso arquivo go.mod deve ficar assim:
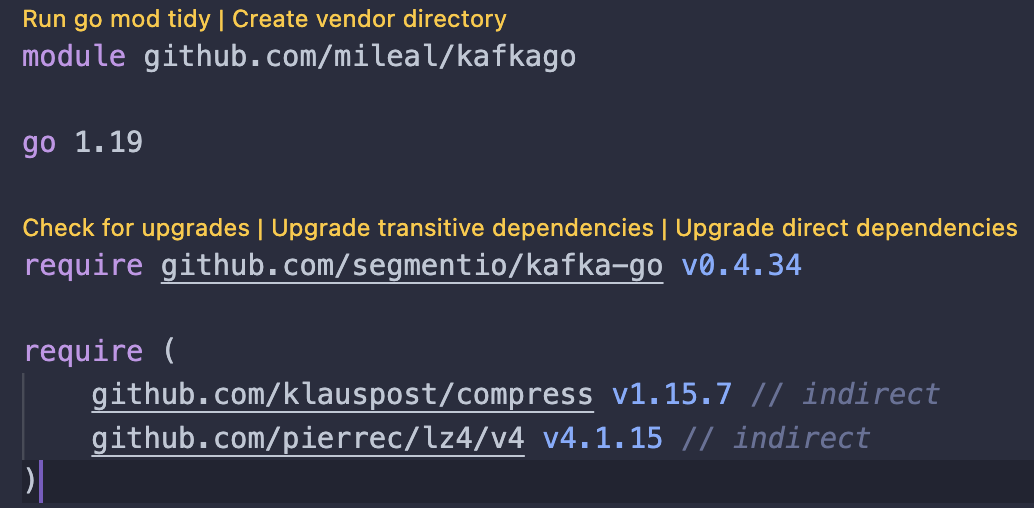

Nosso projeto está tomando forma!
Passo 4: Mensagens em bancos de dados simulados
Vamos agora criar uma função que nos permitirá salvar as mensagens que produzimos nos bancos de dados fictícios. Iremos para nossa pasta db e criaremos um arquivo db.go. Em seguida, escreveremos o seguinte:

Nossa função WriteFile toma como parâmetros o nome do banco de dados (que no nosso caso será um arquivo de texto), o tempo em segundos que queremos que leve para realizar a ação e, por fim, o valor que queremos armazenar.
Passo 5: Criação do nosso microsservicio produtor de mensagens
Agora que já temos toda nossa estrutura pronta e nossa função para armazenar dados, vamos criar nosso primeiro microsserviço produtor, que se encarregará de gerar as mensagens, armazená-las em seu banco de dados e, por fim, enviá-las para a fila de mensagens do Apache Kafka para serem consumidos pelo nosso microsserviço de consumidor.
Iremos para nossa pasta ms-producer e criaremos dois arquivos. O primeiro arquivo se chamará main.go, onde irá nossa lógica, e o segundo arquivo se chamará postgres.txt, que será nossa simulação de banco de dados para o microsserviço produtor.

A primeira coisa que faremos é acessar nosso arquivo main.go e escrever:
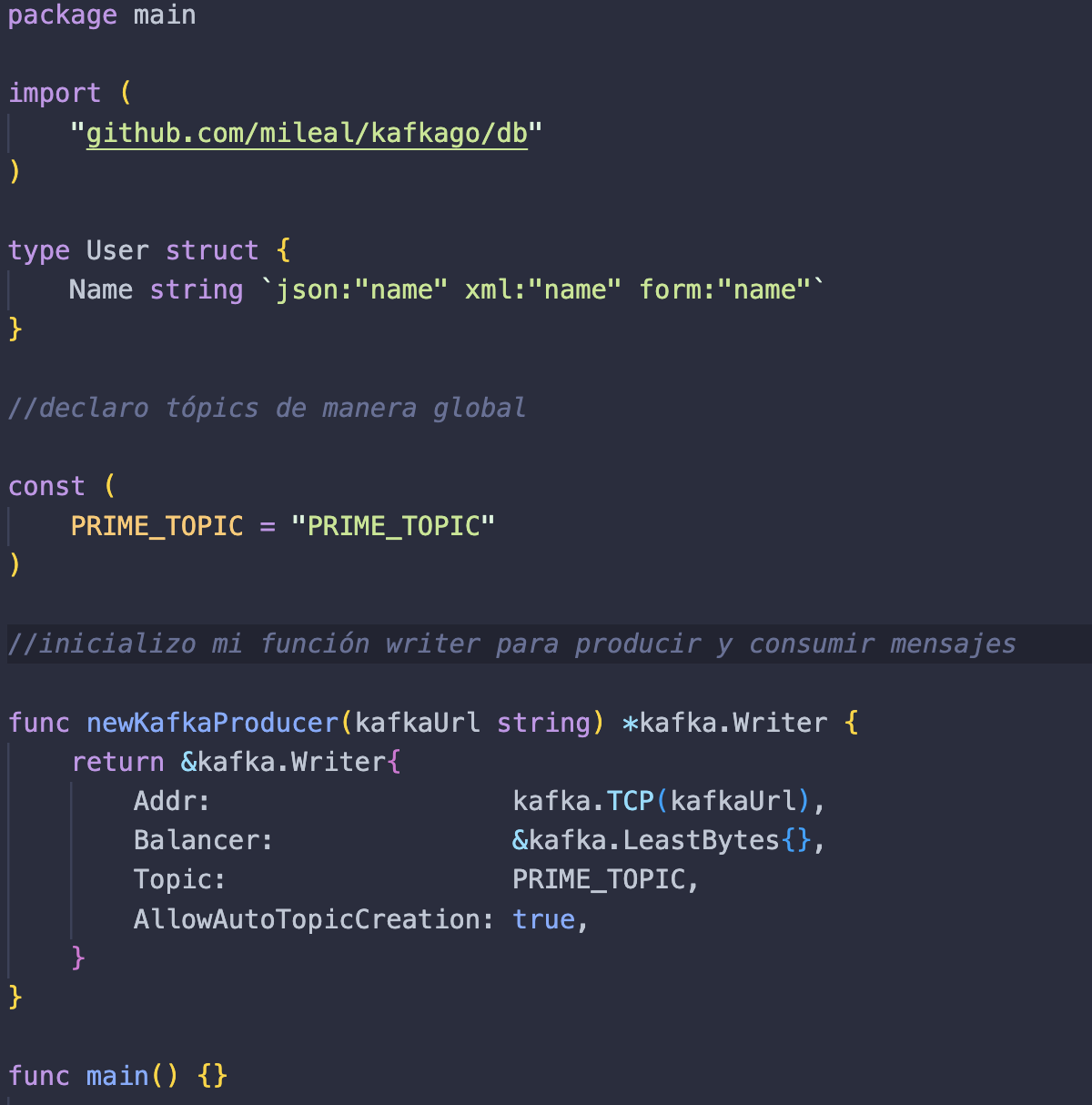
- Vamos importar do nosso módulo db. Para isso devemos escrever a mesma coisa que escrevemos em nosso go.mod, seguido de “/db”.
- Criamos uma estrutura User, que terá um atributo Name. Estes serão os dados que iremos armazenar e que enviaremos ao trocador.
- As mensagens no Apache Kafka não possuem um identificador, portanto são agrupadas por tópico. O que faremos é criar uma variável global chamada PRIME_TOPIC, que será necessária para identificar as mensagens enviadas.
- Criamos uma função newKafkaProducer que nos ajudará a configurar nosso produtor.
Agora vamos desenvolver a lógica. Para fazer isso, construímos nossa função principal da seguinte maneira:
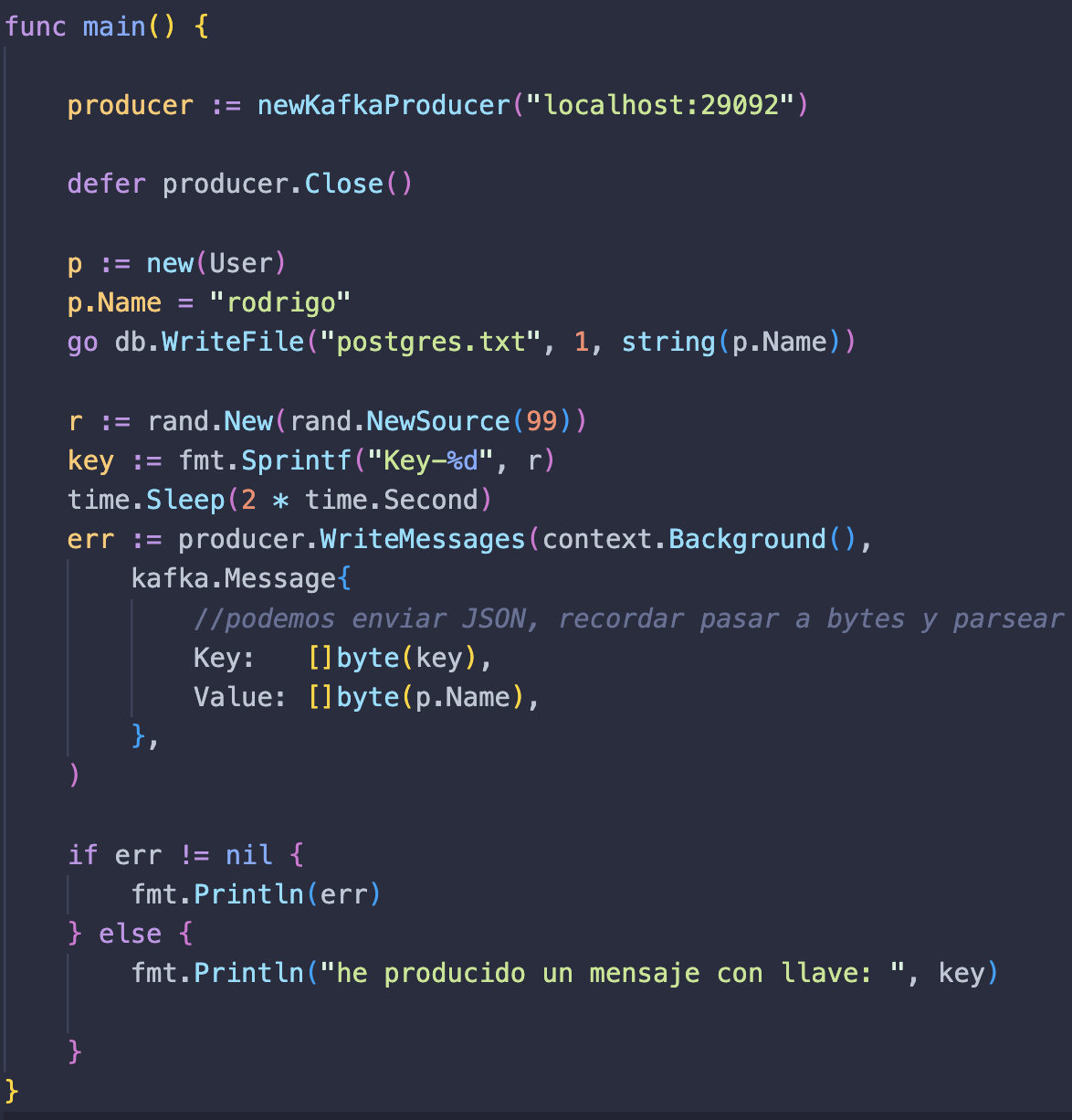
Inicializamos nossa função newKafkaProducer com a url localhost:29092, que é onde nossa imagem Kafka está hospedada. Instanciamos um usuário "p" e damos a ele o nome de rodrigo. Agora vamos usar a função db.WriteFile que criamos em nossa pasta db e passar para ela nosso banco de dados postgrest.txt, dando um segundo para ela fazer a escrita e o valor dos nossos dados, que no caso é p.Name convertido para cadeia de texto.
Criamos uma variável "r" do tipo numeric de valor aleatório para dar um identificador a nossa mensagem; Adicionamos esse valor à nossa variável key. Agora que armazenamos a mensagem em nosso banco de dados "postgres", enviaremos a mensagem para a fila do Kafka. Para isso utilizamos a função producer.WriteMessages, onde passamos um objeto do tipo kafka.Message com nossa chave e valor. Por fim, imprimimos um log que confirma que a mensagem foi produzida e enviada.
Executando nosso arquivo main.go, obtemos uma resposta positiva:

Se revisarmos nosso arquivo postgres.txt veremos que a mensagem rodrigo foi salva corretamente:

Passo 6: Criar nosso microsserviço consumidor de mensagens
Agora que temos mensagens na fila Kafka, o que nos resta é poder consumi-las de outro microsserviço. Para isso, iremos até nossa pasta ms-consumer e criaremos dois arquivos: um será main.go, onde escreveremos toda a lógica necessária para nosso consumidor, e o outro será nosso banco de dados simulado para este microsserviço chamado elasticsearch. json.

Agora iremos ao nosso arquivo main.go em nossa pasta consumidor e digitaremos:
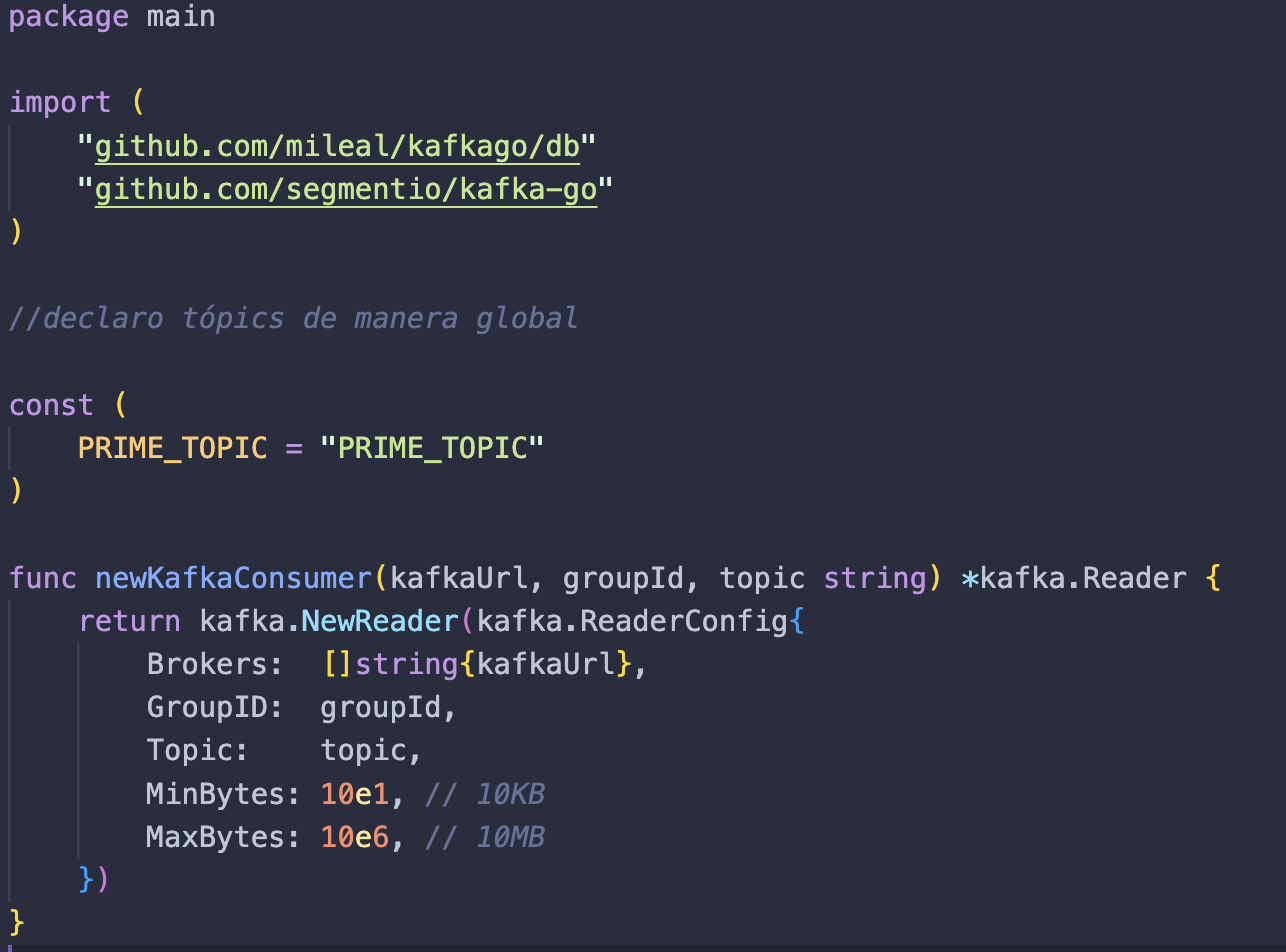
Primeiro importamos o que é necessário. Fazemos quase a mesma configuração do nosso arquivo producer, mas o que faremos de diferente é a nossa nova função newKafkaConsumer, que recebe uma url, um grupo de consumidores e um tópico como parâmetros, fazemos a configuração inicial da nossa função NewReader usando o ReaderConfig função.
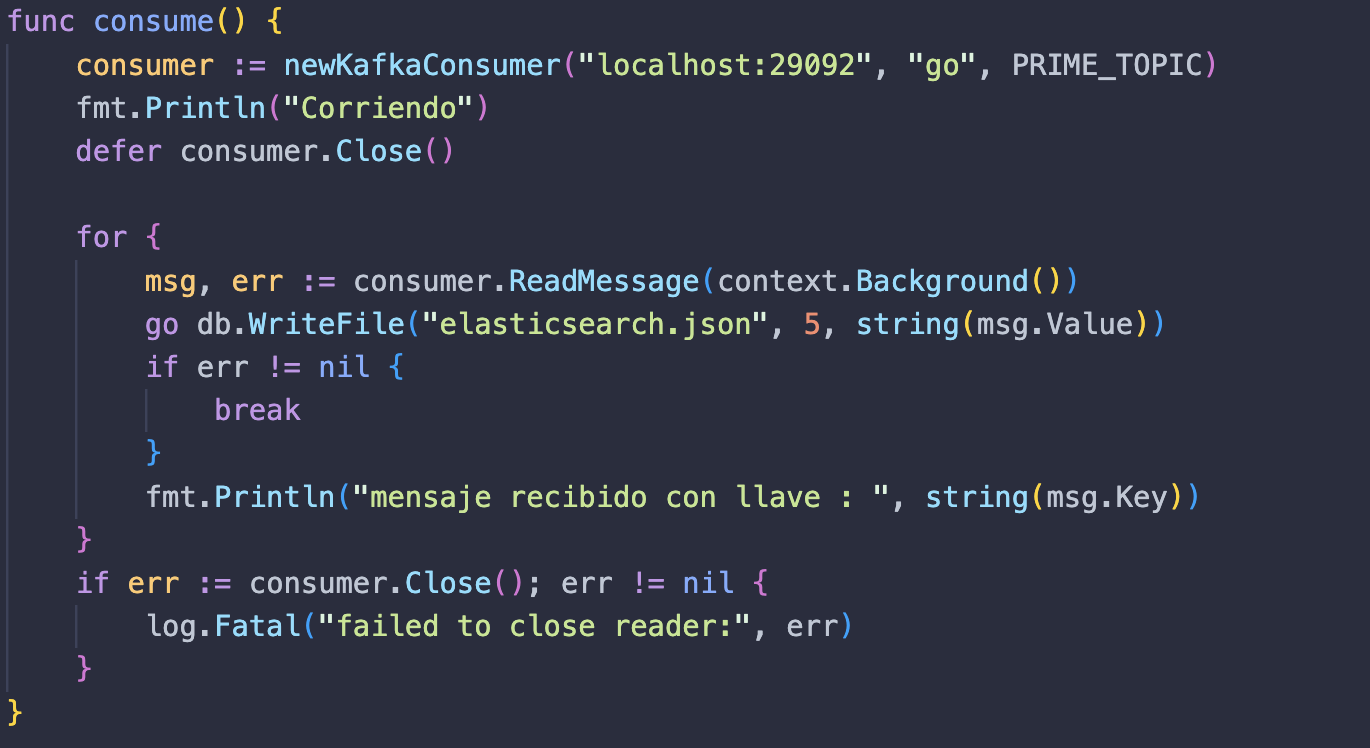
Agora vamos criar uma função consuma, encarregada de armazenar toda a lógica correspondente a consumir as mensagens da fila e escrevê-las no banco de dados. Primeiro instanciamos nossa função newKafkaConsumer para a qual passamos o url localhost:29092, um grupo de consumidores denominado go e um tópico denominado PRIME_TOPIC.
Criamos um loop infinito para verificar constantemente a fila em busca de novas mensagens. Para fazer isso, primeiro criamos uma variável msg que será a mensagem na fila, depois executamos uma go routine com nossa função WriteFile para gravar as mensagens em nosso banco de dados fictício elasticsearch com um atraso de 5 segundos para que possamos ver como funciona , e por fim, imprimimos um log caso recebamos uma mensagem e outro caso algo dê errado.
Chamamos o consumo em nossa função principal e nosso projeto está pronto!

Ao executar os dois microsserviços, podemos ver como podemos trocar mensagens entre eles.


Isso é tudo! Espero que este tutorial tenha sido útil. Até logo!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.