Data skills com KNIME - Parte 1


Nesta série, Desenvolvendo Data skills com KNIME, passaremos por diferentes desafios com suas soluções relacionadas a casos de uso básicos, médios e complexos. Esses desafios, criados por membros da comunidade e pelo pessoal do software com o objetivo de nos ajudar a desenvolver mais e melhores habilidades de análise, fazem parte da primeira temporada do programa “Just KNIME It! Challenges” - 2022.
Para tal, iremos utilizar a KNIME Analytics Platform, um software open source criado sob o paradigma No code/Low Code, tema que iremos desenvolver em artigos futuros com uma abordagem data oriented. Essa plataforma permite que os usuários consultem, transformem, analisem e visualizem dados com praticamente pouca ou nenhuma codificação ou conhecimento básico.
Com uma curva de aprendizado rápida, esta plataforma oferece soluções simples para usuários novatos e um conjunto de ferramentas avançadas de ciência de dados para usuários experientes. Os fluxos são realizados por meio de ações de drag & drop (arrastar e soltar), conectando os nós entre si para produzir os resultados intermediários e finais. Mãos à obra!
O desafio
Para esta primeira parte, o desafio (nível médio) passa pela criação de um fluxo que nos permita visualizar um conjunto de imagens e que, de forma interativa, possamos selecionar, filtrar ou excluir. Neste caso, usaremos um conjunto de imagens aleatórias de Os Simpsons, embora você possa substituir as imagens por outras de seu interesse.
Workflow ou fluxo de trabalho
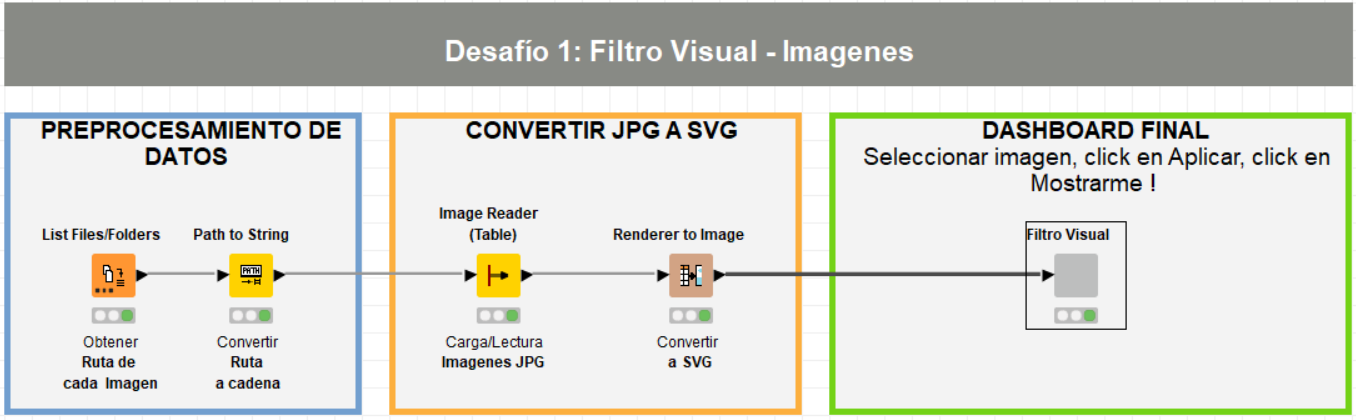
A primeira etapa requer a leitura desse conjunto de imagens de um diretório. Não precisamos que sejam imagens da mesma dimensão ou tamanho, mas é recomendável que sejam imagens do tipo JPG.
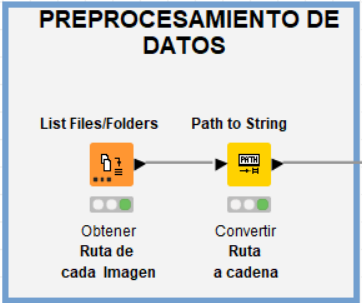
Configuramos o primeiro nó de leitura direcionando-o para o diretório onde hospedamos as imagens para recuperar/listar o caminho de cada uma e depois converter esse caminho para o formato string.
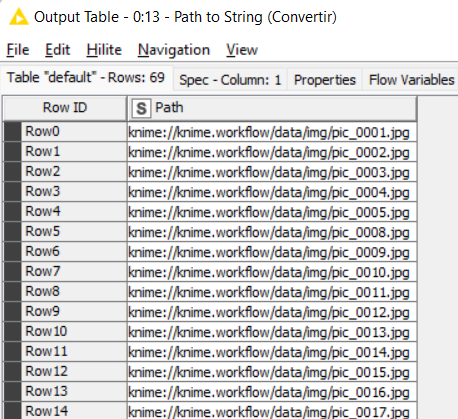
O resultado é uma tabela onde em cada registro temos o endereço ou rota para cada imagem.
O próximo passo é pegar a própria imagem e carregá-la na plataforma, para que possamos visualizá-la. Para renderizar as imagens em uma tabela dinâmica, devemos primeiro convertê-las em SVG (Scalable Vector Graphics - formato de arquivo vetorial amigável para a web).

O resultado da conversão é novamente uma tabela com as imagens prontas para serem colocadas em uma tabela dinâmica.

A última etapa do fluxo consiste no desenvolvimento de um componente que nos fornecerá a funcionalidade de criar dashboards ou tabelas analíticas. Para isso, encapsulamos duas tabelas dinâmicas (Tile View ou Mosaics), um filtro e um botão Show Results, além de outros que nos mostrarão os títulos e subtítulos:

Na imagem a seguir, podemos ver a composição interna do componente:

Ao abrir ou desdobrar o nodo, na janela de visualizações selecionamos manualmente aquelas imagens onde Marge Simpson não aparece e as filtramos, para que fiquem apenas as imagens onde ela aparece e então clicamos no botão Apply (parte inferior), que aplicará o filtro dinâmico.
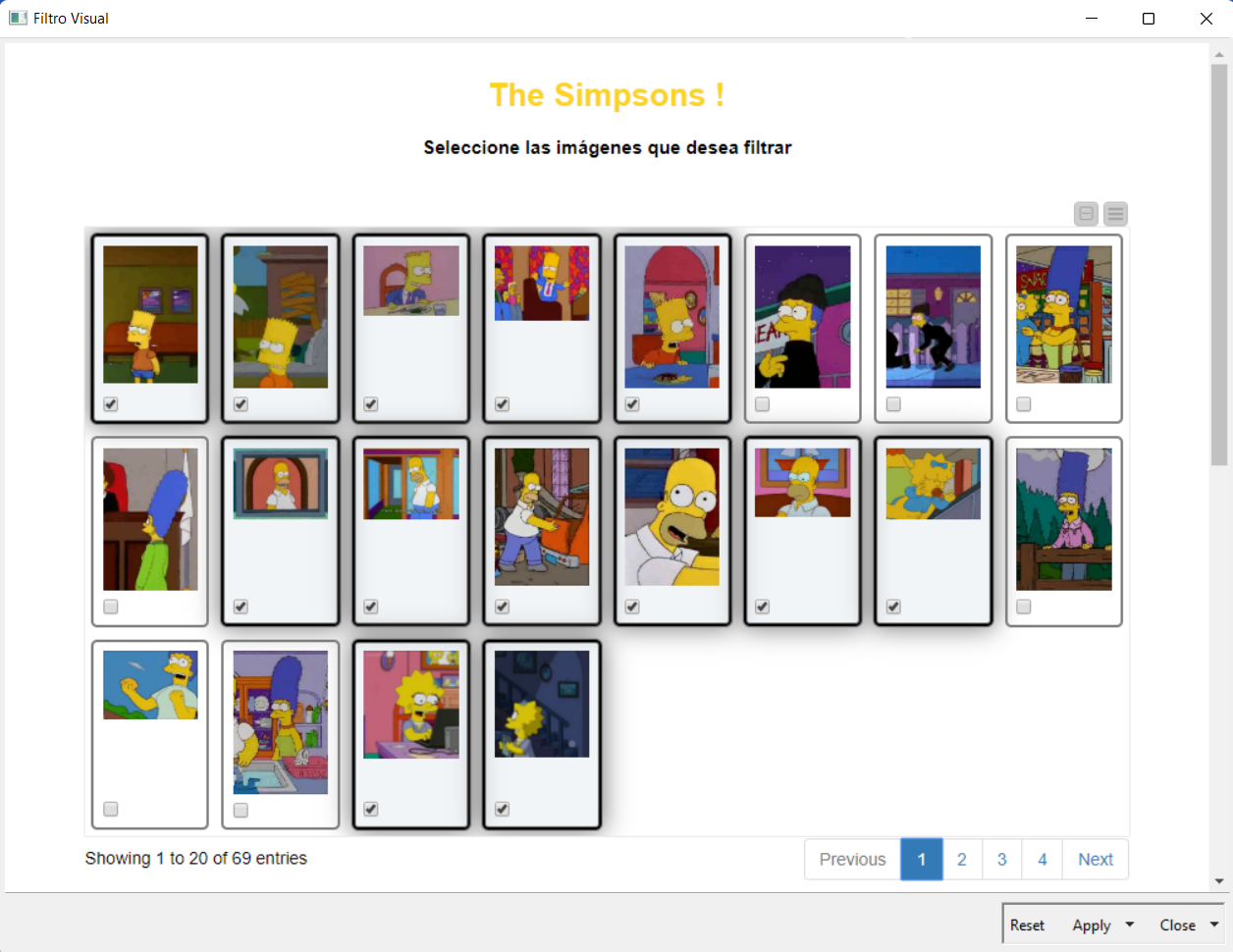
Por fim, o último passo é clicar no botão amarelo Mostre-me!, que atualizará a segunda tabela dinâmica e mostrará apenas as imagens que não foram selecionadas no passo anterior.

O fluxo completo é o seguinte:
Como você pode ver, nem uma única linha de código! Em quatro etapas criamos um fluxo simples de leitura, processamento e visualização de imagens.
O que aprendemos com esse desafio?
Usando os nós List Files/Folders, Path to String, Image Reader (Table) e Renderer to Image, aprendemos a carregar imagens para o espaço de trabalho, lendo previamente o caminho de localização de cada uma delas, para renderizá-las ou convertê-las em outra formato (SVG) e por fim, com o Componente, criamos um visualizador de mosaicos simples para aplicar os filtros nas imagens.
O nó Listar Arquivos/Pastas não serve apenas para leitura de caminhos de imagem, mas para qualquer formato de arquivo suportado pela plataforma (TXT, CSV, XLSX, JPG, etc.), para posterior manipulação.
O Componente é uma coleção ou grupo de nós que nos permite agrupar subtarefas (simplificar os nós no fluxo de trabalho principal) ou criar painéis analíticos. Nas próximas edições, veremos aplicações mais complexas dos componentes.
Casos de uso
Na maioria das vezes, os fluxos de trabalho relacionados à análise de imagens são desenvolvidos para processá-las e obter mais informações, classificar, corrigir ou segmentar imagens, determinar padrões ou identificar objetos específicos de interesse. Os exemplos mais clássicos são aqueles dentro da área de Computer Vision, normalmente aplicada à análise de imagens médicas, onde complexos algoritmos de Redes Neurais são utilizados para analisar padrões e determinar possíveis casos positivos de câncer em pacientes, bem como a análise em tempo real de feeds de vídeo.
Outros exemplos práticos relacionados
Neste link para o KNIME Hub (Portal de soluções e espaços colaborativos), você encontrará a versão original desta solução para o desafio publicamente (em inglês).
Outro exemplo mais complexo usando o conceito de seleção de imagens lado a lado é o seguinte; onde uma imagem pode ser decomposta em suas cores dominantes usando o serviço Google Cloud Vision API.
Conclusão
Este é o primeiro artigo de uma série de 40 desafios com soluções, onde exploraremos diferentes habilidades de análise de dados de vários tipos, passando pelas melhores práticas para visualização de dados, manipulação de arquivos e noções básicas de mineração de dados.
Como prévia, no próximo artigo veremos como manipular arquivos lendo um arquivo geral e particionando-o em arquivos específicos por Ano e Mês em diferentes diretórios.
Independentemente da sua formação profissional, esta é uma excelente oportunidade para conhecer uma plataforma que o ajudará a analisar a informação do dia-a-dia.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.