Disponibilizando um modelo de classificação (Keras + Flask + Heroku)


Desde que comecei a estudar Machine Learning pensei em como iria disponibilizar o modelo de classificação que treinei para que seja acessado por usuários ou aplicações. A principal barreira que me deparei foi o fato de que a aplicação web que faria uso do modelo de classificação não era feita em Python, com isso não foi possível simplesmente chamar o classificador em uma controller ou service.
Nesses casos, a solução foi a criação de uma API que servisse apenas ao propósito de receber uma requisição com os atributos de um novo exemplar e retornar o resultado gerado pelo classificador. Como o propósito da API é muito simples, busquei um framework que atendesse apenas a este propósito e com isso me deparei com o Flask.

Flask
O Flask é um micro-framework escrito em Python que simplifica o desenvolvimento de APIs, permitindo iniciar um projeto de forma simples e ir evoluindo à medida que forem aparecendo novas necessidades, como a adição de um ORM, caso seja necessário persistir informações em um banco de dados.
Criação e persistência de um modelo pré treinado
Iniciaremos pela implementação do modelo de classificação e como o foco do artigo é a disponibilização do modelo, não darei tanta ênfase a parte de Machine learning. Primeiro devemos criar um novo diretório para nosso projeto, recomendo a utilização do virtualenv para isolar a instalação das bibliotecas e do Python que iremos utilizar.

Com o projeto criado, devemos inicializar o repositório git para que os arquivos sejam versionados através da execução do comando git init dentro do diretório do projeto. Com o repositório git criado, iremos alterar o arquivo .gitignore para que os arquivos gerados pelo virtualenv sejam ignorados.

Como iremos utilizar a base de dados IRIS, que é uma base de dados utilizada largamente na avaliação de modelos de classificação, a forma mais simples de carregá-la é através da biblioteca scikit-learn. A outra biblioteca utilizada será o tensorflow-cpu, que é uma biblioteca utilizada em projetos de Deep learning, porém iremos utilizar uma API de alto nível chamada keras que simplifica o desenvolvimento de redes neurais.
Antes de continuarmos, vale à pena esclarecer o motivo de estarmos trabalhando com o tensorflow-cpu e não com o tensorflow. Primeiramente, a ausência de GPU e das instalações necessárias para que o tensorflow seja executado através da GPU, e em segundo lugar, o tamanho máximo permitido pelo Heroku para uma aplicação após instalação de suas dependências e compactação, que no momento da escrita deste artigo é de 500MB e apenas a biblioteca tensorflow possui aproximadamente 600MB. Contudo, é possível utilizar o tensorflow durante o desenvolvimento do modelo fazendo uso de GPU durante as etapas de treino e teste, e uma vez finalizado, utilizar o tensorflow-cpu em produção.
Após executar o comando pip install scikit-learn tensorflow-cpu para instalar as bibliotecas utilizadas, iremos criar um novo arquivo chamado classifier.py e nele iremos treinar e salvar nosso modelo de classificação.
O código abaixo define uma rede neural contendo duas camadas ocultas com 128 e 64 neurônios, respectivamente. Ambas as camadas aplicam a função de ativação ReLu e têm os valores dos pesos inicializados utilizando a técnica RandomNormal que está fixada com um SEED para que o resultado seja reproduzível. Uma vez que a base IRIS contém três classes, a ultima camada possui três neurônios e utiliza a função de ativação softmax.
Após feita a compilação e o treinamento da rede neural, atingiu-se uma acurácia de 0.966 no grupo separado para teste, o que é o suficiente para o objetivo deste artigo. Com isso, ao final do script salvamos um arquivo chamado model.h5 que contém nosso modelo treinado. Existem outras métricas e arquiteturas que podem ser testadas e podem gerar resultados melhores, porém nosso foco é a disponibilização de um modelo já treinado e não encontrar o melhor modelo de classificação.


API Flask
Com nosso modelo treinado, chegou a hora de criarmos uma API para disponibilizá-lo. Como dito anteriormente, iremos utilizar o micro-framework Flask para criação da API, assim o primeiro passo é instalar o Flask executando o comando pip install flask.
Uma vez instalado, será criado um arquivo chamado main.py, contendo o código a seguir. Neste código é declarada a rota /predict que responde ao método HTTP POST, e ao receber uma lista de atributos de um exemplar da base IRIS, retorna uma lista contendo a probabilidade para cada uma das classes possíveis.


Como descrito nos comentários do código, seguem alguns pontos importantes:
- o modelo é carregado antes de inicializar a aplicação, uma vez que este processo é custoso e fazê-lo durante cada requisição aumentaria consideravelmente o tempo de resposta da API;
- o resultado do método keras.Sequential.predict() deve ser convertido para um objeto do tipo lista, uma vez que a função jsonify não consegue serializar objetos numpy.
A aplicação é iniciada a partir da execução do comando python main.py, e fica disponível em localhost:5000. Para testar a API, basta fazer uma request executando a chamada cURL a seguir ou através de aplicações como Postman ou Insomina.

Deploy Heroku
Com a conclusão da API, chegou o momento do deploy que será feito na plataforma Heroku. O Heroku é uma Platform as a Service (PaaS) que disponibiliza um ambiente cloud utilizado para o provisionamento de aplicações web. Devido a simplicidade e baixa necessidade de configurações, é uma boa escolha para quem busca disponibilizar uma aplicação web sem dedicar muito tempo a configuração de ambiente.
Antes de criar a aplicação no Heroku, é necessário que sejam feitos alguns ajustes na API para que esta fique pronta para o ambiente de produção. O primeiro passo é instalar o servidor WSGI gunicorn atendendo ao warning exibido ao iniciar a aplicação. Tal mensagem contém: “WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instea.”, informando que o servidor atual deve ser utilizado apenas em desenvolvimento e para o ambiente de produção, deve ser adicionado um servidor WSGI próprio, que nesse caso será o gunicorn.
Ao final da instalação do gunicorn, iremos gerar um arquivo .txt com todas as dependências de nossa aplicação executando o comando pip freeze > requirements.txt. Note que foi gerado um arquivo chamado requirements.txt que contém a lista de dependências bem como a versão específica de cada biblioteca.
Por fim, é necessário definir que a aplicação seja iniciada utilizando o servidor gunicorn, isto é feito adicionando uma linha com a configuração web: gunicorn main:app a um arquivo chamado Procfile. O arquivo Procfile é utilizado pelo Heroku para definir as configurações de inicialização de um ambiente.
Como faremos o deploy através da integração que o Heroku possui com o Github, será necessário fazer um commit com as alterações até aqui e criar um novo repositório como o que criei com o código deste projeto.
Com sua conta no Heroku criada através do link, chegou o momento de fazer o deploy da aplicação. Ao clicar no botão new e selecionando a opção Create new app, você será redirecionado para a tela de criação de um novo app. Lembre-se de que não existem mais Dynos gratuitos, e um Dyno básico é o suficiente para reproduzir a aplicação descrita neste artigo e custa em torno de sete dólares por mês.

Agora deve ser preenchido um nome para a aplicação, que no meu caso foi `iris-prediction-api`. Como o nome é único, deve ser escolhido algo que faça sentido para sua aplicação.

Com o nome da aplicação definido, chegou a hora de enviar nosso código ao `Heroku`. É possível fazê-lo através de um cliente de terminal que o próprio `Heroku` disponibiliza, porém faremos via integração com o `Github`. Com isso, clique na opção `Github` presente na sessão `Deployment method` e siga os passos para dar acesso ao `Heroku` a seus repositórios presentes no `Github`.
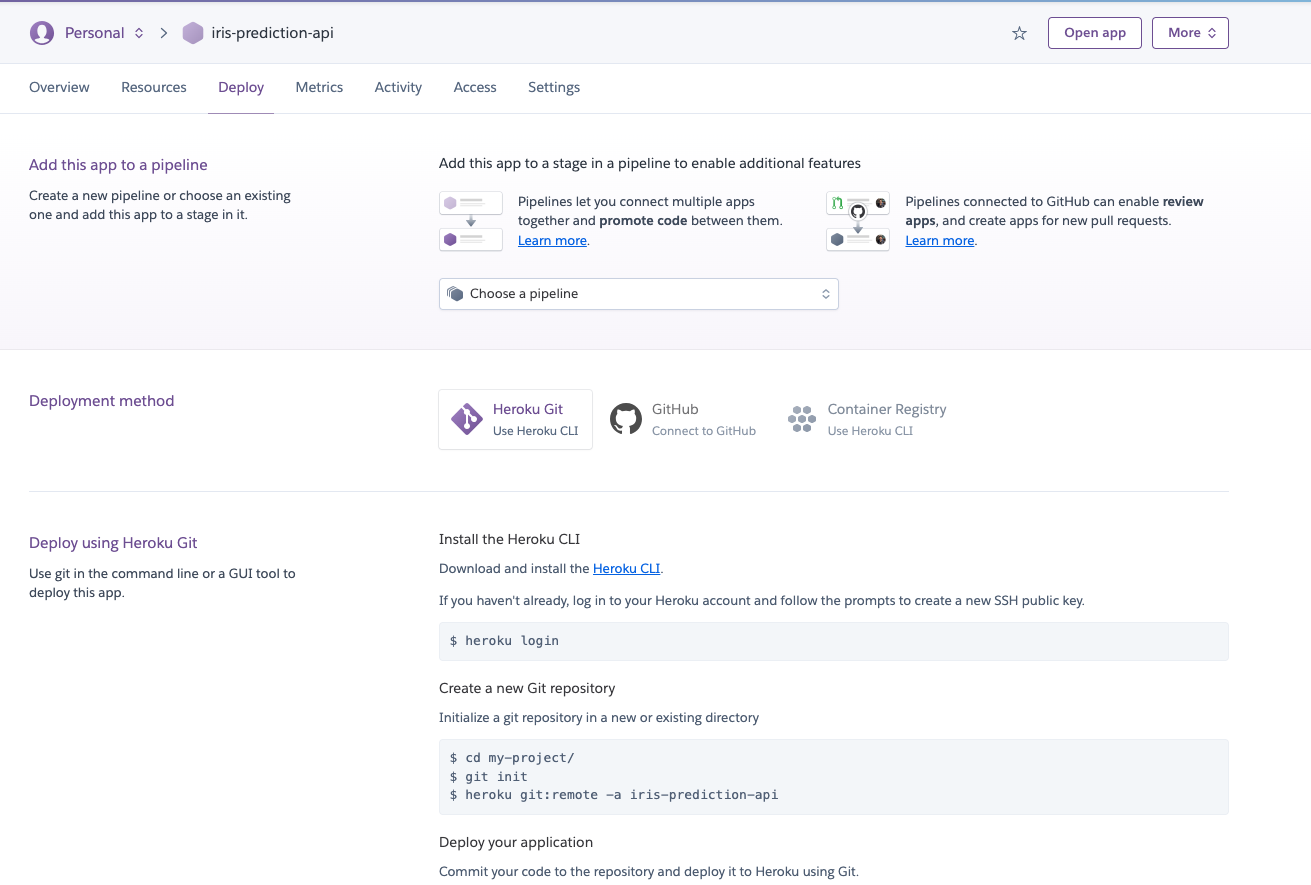
Uma vez que a integração estiver concluída, utilize o filtro para selecionar o nome do repositório e clique em `connect`. Após conectado com o repositório, selecione a `branch` que contém o código de produção, que no meu caso é a branch `main` e clique no botão `Deploy branch` para que seja iniciado o processo de deploy. Note que existe uma opção que permite ligar o deploy automático e, com isso, sempre que a branch selecionada for atualizada será feito um novo deploy automaticamente.
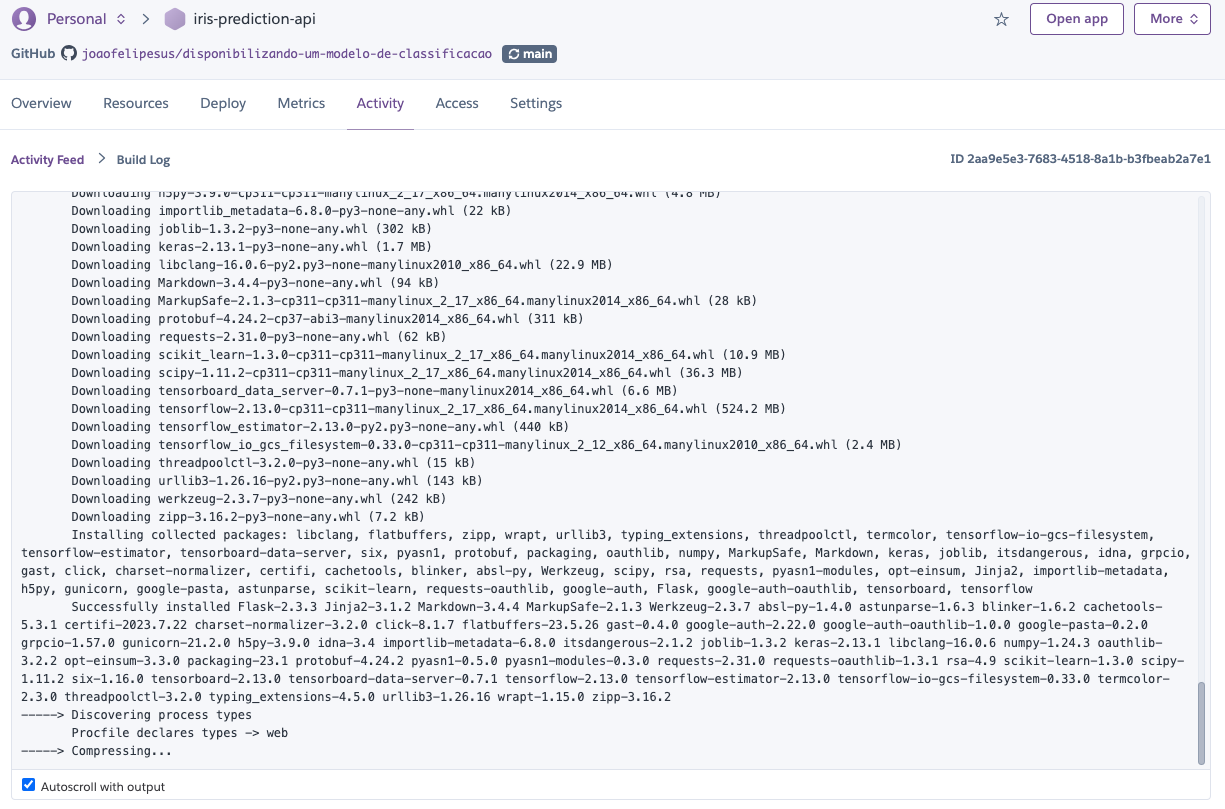
É possível acompanhar os passos que estão sendo executados bem como o status do `deploy`.
Com o fim da etapa de deploy, chegou o momento de testar se a API está funcionando corretamente. Clique no botão `Open app` e copie a `URL` da aba que foi aberta. Esta é a `URL` que aponta para a `API` e com isso é possível fazer uma requisição via `cURL` apontando para o servidor de produção.


Por fim,temos uma API `Flask` que disponibiliza um modelo de classificação para que seja utilizado por outros apps. O código utilizado como exemplo ao longo do artigo está neste repositório.
Até o próximo artigo!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.