Do Web Scraping à Automação com Python


Atualmente, a automação de processos digitais tem tido um grande boom dentro das empresas, pois melhora a produtividade em seus diferentes departamentos. Graças à sua contribuição para deixar de lado tarefas repetitivas e ajudar a equipe a se concentrar em atividades que agregam valor ao negócio, conhecemos esses processos como RPA (Robotic Process Automation).
Essas atividades podem variar desde tarefas simples como clicar, preencher formulários ou fazer login em um aplicativo, até extrair, limpar e manipular informações, entre outras.
O processo ou técnica de extração de informações dentro de um site é chamado de Web Scraping, enquanto o software ou programa de raspagem é chamado de bot ou spider. Essa técnica é utilizada por muitas empresas para obter informações valiosas, seja para monitorar a concorrência, otimizar preços ou gerar um banco de dados para posteriormente criar um modelo de Machine Learning.
Atualmente, existem várias ferramentas de automação que incluem a opção de Web Scraping. Isso inclui Power Automate, UiPath e Blueprism, que executam processos simples e mais complexos. Uma das desvantagens de apenas aprender sobre automação de processos com essas ferramentas é que usá-las por um longo período ou implementar determinados componentes requer uma licença.
No entanto, para realizar Web Scraping ou processos de automação, não é necessária uma ferramenta especializada, mas podemos fazê-lo através de código.
Entre as linguagens de programação com bibliotecas especializadas em Web Scraping está o Python, cujo alto nível tem sido muito popular ultimamente por possuir bibliotecas de código reutilizáveis que permitem gerar código para múltiplas finalidades, além do fato de sua sintaxe ser muito intuitiva e fácil , em comparação com outras línguas.
Entre essas bibliotecas está o Beautiful Soup, que extrai dados de arquivos HTML e XML. Há também o Selenium, um pacote que facilita o acesso a todos os recursos do Selenium Web Driver e a interação com os componentes dentro do servidor da página requerida.
Quais as ferramentas necessárias para começar no Web Scraping?
- Um IDE que suporta Python. Neste tutorial, usaremos o VS Code.
- Instalação da Beautiful Soup 4 e pedidos.
Parte 1
Embora você também possa usar o Anaconda Navigator ou o Google Colab, neste caso usaremos um notebook em VS Code.
1- Se você ainda não tiver o Python habilitado, poderá instalar a extensão na opção de extensões no VS Code. Mais tarde, instalaremos o notebook Jupyter.

2- Vamos gerar um novo arquivo do tipo notebook Jupyter.
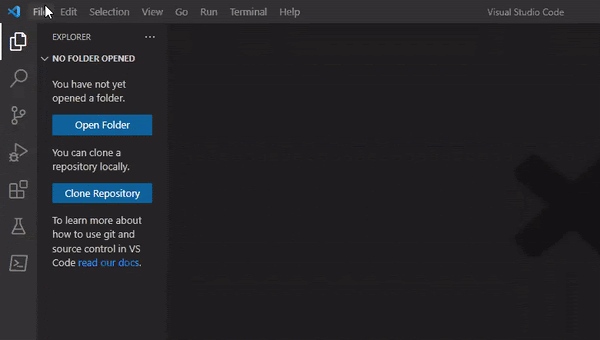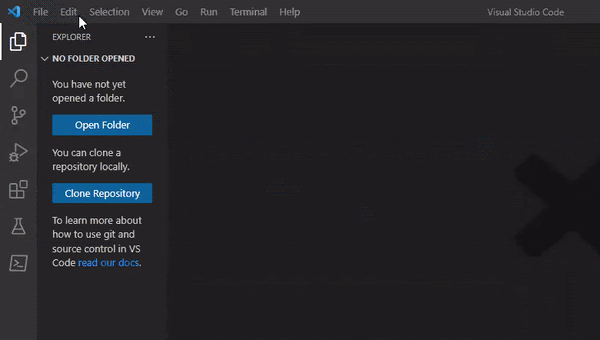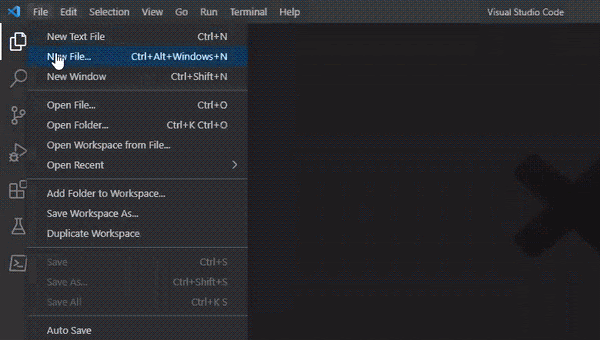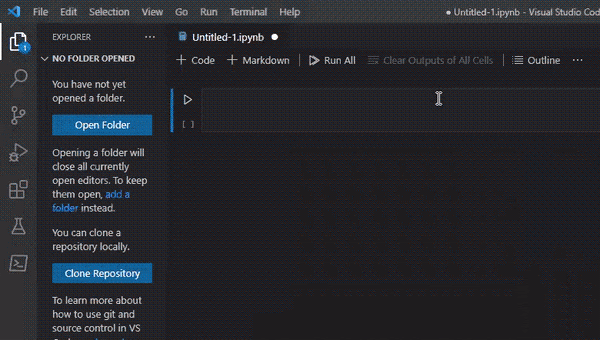
3- Para a instalação das bibliotecas no terminal, escreveremos o seguinte.
pip install requests
pip install beautifulsoup4
4- Agora vamos importar as bibliotecas instaladas:
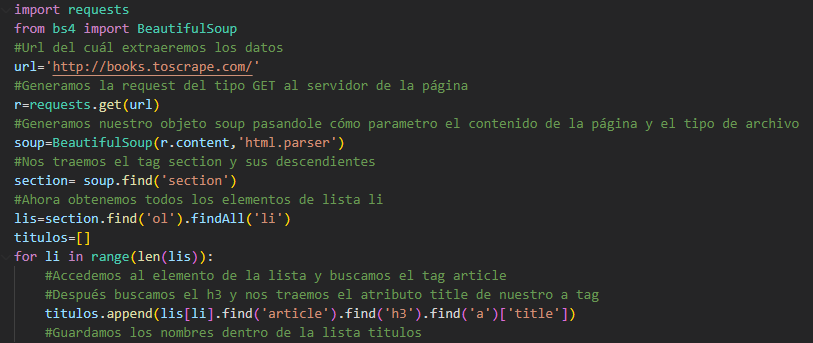
5- Para este exemplo, usaremos um link dedicado http://books.toscrape.com/ , retirado da página toScrape.
Uma vez que tenhamos a url, vamos gerar a requisição do tipo get para o servidor da página com a biblioteca de requisições, então geramos nosso objeto, passando o conteúdo da requisição e o tipo de documento, seja HTML ou XML, como parâmetros.

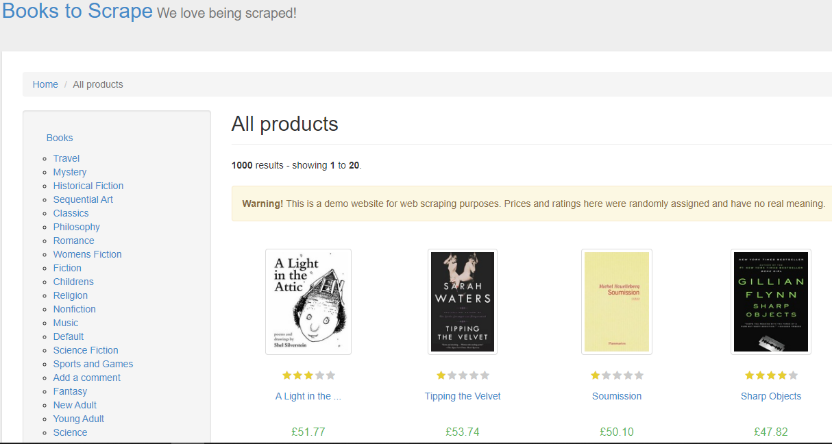
6- Vamos ao nosso navegador para a página e a analisamos.
Dentro dele vemos que temos livros com diferentes categorias. São um total de 1000 livros, distribuídos 20 livros por página com um total de 50 páginas.
7 - Agora apertamos o botão direito do mouse, clicamos em Inspecionar e procuramos a etiqueta que contém os livros. Se pressionarmos CTRL+SHIFT+C no teclado nos livros, ele nos mostrará o rótulo onde eles estão.
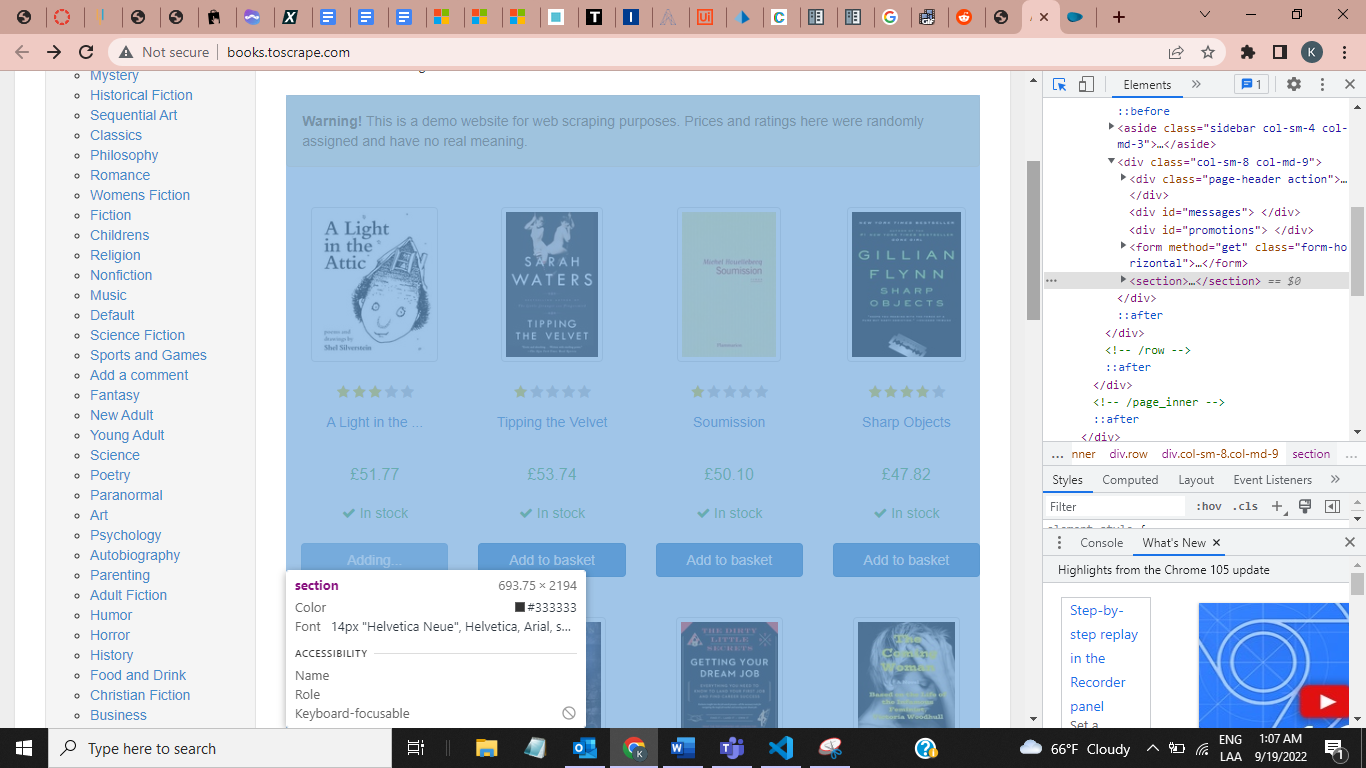
- Vemos que o rótulo é do tipo seção. Então voltamos ao nosso caderno e procuramos por essa tag.
- Para procurar a tag <section></section> e trazer de volta tudo que ela contém, usamos o método find(), que procura em nosso objeto a primeira tag com esse nome e seus descendentes.

8- Agora vamos extrair o nome de todos os livros. Para fazer isso, voltamos ao nosso navegador e vemos em qual tag ele está.
Entrando na tag section, vemos que todos os livros estão na forma de uma lista ordenada dentro da nossa tag <ol>. Portanto, agora sabemos que devemos extrair todas as tags <li> e delas obter o nome de cada livro.
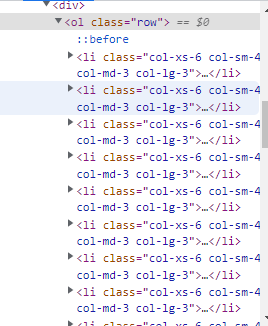
Em seguida, analisamos nossas tags <li> e vemos que todas têm uma estrutura semelhante. Este tem uma tag <article> como descendente e dentro dela temos mais 4 tags que contém:
- Uma tag do tipo <div> com a imagem.
- Marque <p> com a classificação do livro.
- Um título <h3> com o nome do livro.
- Um <div> com o preço.
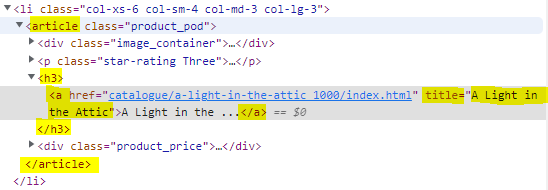
Ao analisar a tag <h3>, notamos que dentro dela temos uma tag <a> com 2 atributos href: link para o livro e título, que contém o nome completo do livro, que nos interessa extrair.
Uma vez conhecido o caminho para extrair os dados necessários, geramos o código.
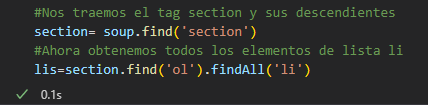
9- Para extrair os elementos da lista <li> para nosso objeto de seção gerado, implementamos o método findAll(), que reúne todos os elementos que encontra com esse mesmo tipo de tag.
10 - Agora vamos iterar através do nosso objeto lis(a list) e extrair os nomes dos livros. Para isso, dentro de um loop for (para percorrê-lo), usaremos o tamanho da lista. O código funciona da seguinte forma:
- Obtendo o len da lista, obteríamos que é 20.
- Se não especificarmos de onde a função de intervalo começa, o padrão é o elemento 0.
- O laço for irá do elemento 0 ao elemento 19. Assim, teríamos 20 elementos.
- Obtemos o enésimo elemento de nossa lista e, dentro dele, procuramos o descendente chamado <article>. Uma vez dentro da tag <article>, vamos até a tag <h3> e a tag <a> pegando o atributo title como valor e imprimindo.
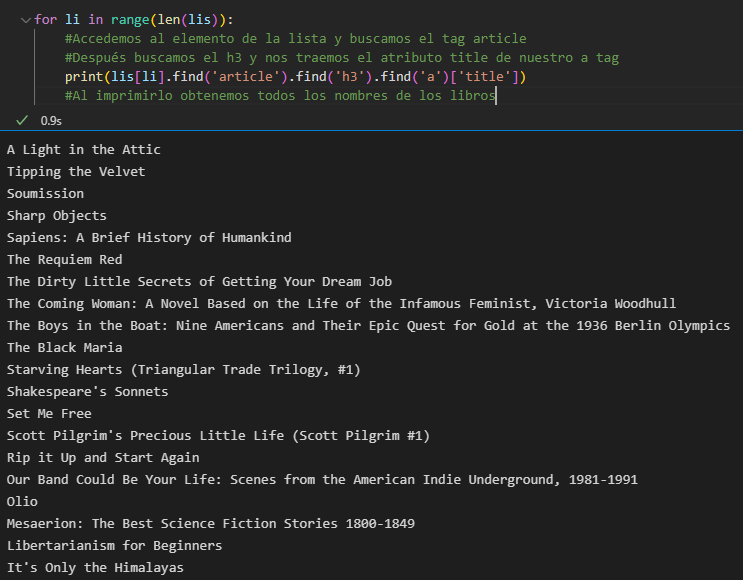
Contando os elementos impressos, notamos que são os 20 nomes dos livros. Posteriormente, inserimos esses valores em uma lista com o método append() e é assim que nosso código final ficaria:
A execução da célula nos dará nossa lista de títulos de livros.
Feito isso, fica mais fácil obter os outros componentes do livro, como preço, classificação, etc.
O que aconteceria se, em vez de nos trazer todos os livros, aparecesse os livros apenas da categoria “Viagem”?
Nesse caso, poderíamos obter a url dessa categoria de maneira semelhante à forma como obtivemos o nome do livro, mas ao fazer isso corremos o risco de que em algum momento o formato ou estilo do documento HTML seja alterado. O melhor seria pesquisar o nome da categoria e clicar nela, certo? Para realizar essas interações, é necessário utilizar o Selenium WebDriver. Que é um ambiente de teste na web.
Parte 2
A partir daqui, realizaremos mais processos de automação. Começaremos com um simples “clique”. Dentro do terminal do nosso projeto, instalamos o seguinte:

É necessário instalar o driver web do navegador a ser utilizado. Desta vez, instalaremos o driver da web para o Chrome. Para saber a versão do nosso navegador:
- Abra o navegador Chrome.
- Clique nos 3 pontos que aparecem acima do lado direito.
- Clique em Configurações.
- Em Configurações, selecione Sobre o Chrome. Uma vez lá, veremos o seguinte:
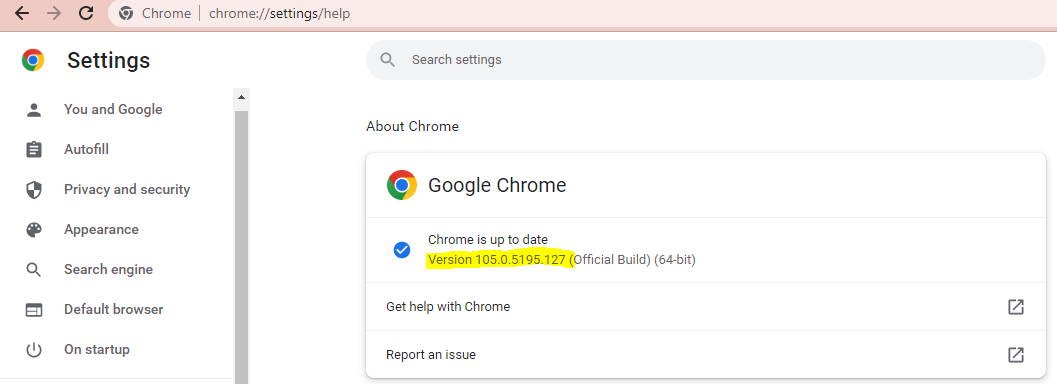
Agora que sabemos qual é a versão, vamos para a página do Chromedriver e baixamos a correspondente.
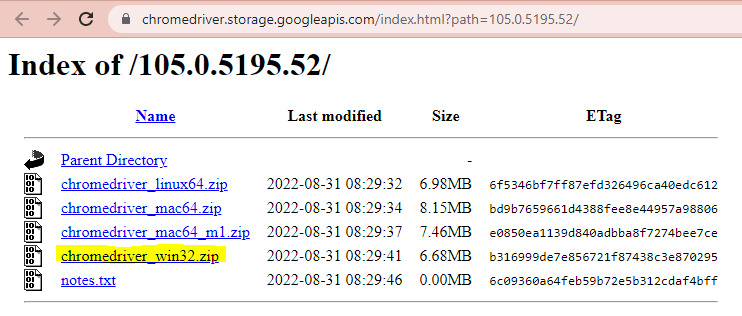
Uma vez que o arquivo.zip é extraído, colocamos nosso driver na pasta do projeto.
Agora voltamos ao passo a passo:
1- Importamos webdriver Selenium.
2- Geramos nosso sistema de teste (declaramos nosso driver web).
3- Maximizamos a tela e carregamos a página. Isso é feito como uma boa prática, pois quando lidamos com páginas responsivas, o código da página pode mudar, portanto, maximizando-o desde o início, mantemos a fonte original.
4- Ao carregar a página para o driver web, exibiremos exatamente a página que passamos para ele. Parece que sim, mas o que realmente obtemos é uma cópia do servidor em nosso ambiente de teste.
Neste ambiente de teste podemos gerar interações com o servidor como se estivéssemos inserindo manualmente, sejam entradas de teclado ou mouse, implementando apenas algumas linhas de código.
5 - Antes de pensarmos que perdemos todo o progresso do código anterior, voltamos ao nosso notebook e geramos nosso objeto novamente, mas desta vez passando o driver como parâmetro.
Dessa forma, se adicionarmos as linhas de código acima, o código funcionará da mesma maneira.

6- Agora sim. Para clicar, usaremos o método find_element_by_link_text(), que procura o texto dentro do ambiente e dá opções, dependendo do tipo.
Procuramos nossa categoria Viagem usando o método find_element_by_text() e clicamos:

A razão pela qual pesquisamos diretamente o texto é porque existem vários elementos com a mesma tag, portanto, pesquisar a categoria desde o início torna nosso processo mais rápido e limpo.
Outra vantagem é que ao realizarmos Web Scraping devemos considerar que as páginas estão atualizadas e podem alterar seu código fonte, por isso é importante programar o bot pensando nessas possíveis alterações futuras e mitigá-las, pois mesmo que o código fonte mude, o nome da categoria não será alterado.
Vamos ao nosso ambiente para ver o que aconteceu.
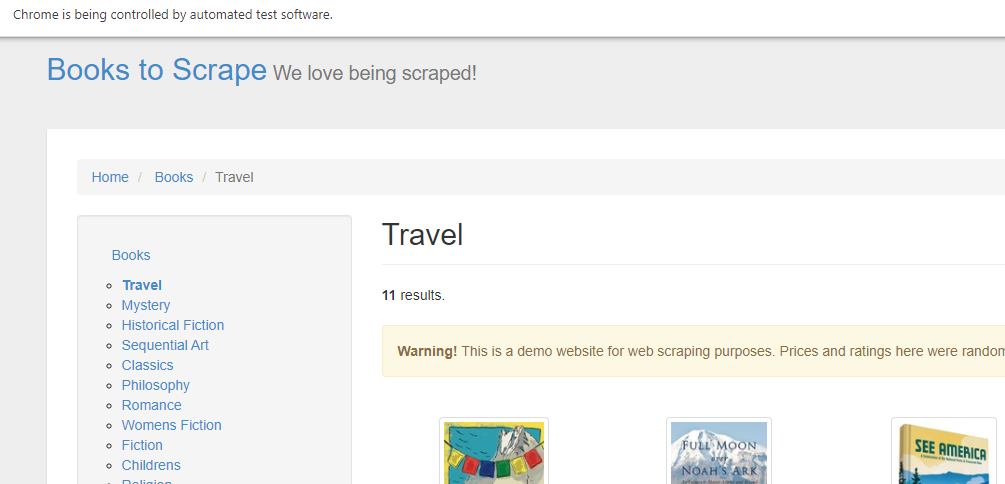
Estamos na categoria Viagem!
Bem fácil, certo? Em posts futuros veremos mais métodos para tirar proveito do Selenium, desde fazer login, navegar entre páginas aninhadas, selecionar dropdowns, preencher formulários e muitos outros.