Faça perguntas ao seu PDF usando LangChain, LLaMA 2 e Python


Vivemos uma época incrível. Os Large Language Models (LLMs) começaram a cobrir as notícias relacionadas à Inteligência Artificial (IA), e isso promove o aumento das possibilidades de aplicações. Um exemplo são os chats inteligentes como o ChatGPT da OpenIA, que são grandes modelos de aprendizagem que fornecem respostas por meio do uso de vastos recursos disponíveis na Internet. E, embora as respostas nem sempre sejam confiáveis, elas podem ser de grande ajuda em diversas áreas. Embora os aplicativos LLM sejam usados como chats gerais para fazer perguntas e receber respostas, eles também podem ser combinados, por exemplo, interagindo com um arquivo PDF.
No mundo académico é normal que cada cientista tenha que ler vários artigos (papers) toda semana para se manter atualizado em sua área. E, não só académicos, também se aplica a quem cultiva a curiosidade. Não seria conveniente ter um assistente que nos ajudasse a encontrar os pontos-chave de um artigo, que também nos fornecesse um resumo, uma espécie de primeira aproximação ao texto, para evitar a leitura de um artigo que talvez não seja o que nós estamos procurando? Bem, hoje, graças aos LLMs, agora é possível.
Neste artigo vou explicar o que são LLMs, em particular Llama 2, um LLM de código aberto gerado pela Meta (ex Facebook). E a ferramenta LangChain, o que nos permite interagir com este e outros modelos de forma fácil e divertida.
Para os exemplos usaremos Python devido à sua facilidade de uso. Embora LangChain possua interfaces para diversas linguagens de programação.

Large Language Model
Entre os vários tipos de LLM existentes, há um que nos interessa: aquele que, dada uma sequência de texto (por exemplo, uma pergunta), prevê uma ou mais palavras. Conhecido como Decoder LLMs. E, ChatGPT é um deles, isso nos permite responder nossas perguntas como “Qual a melhor estratégia para aprender a programar?”, ou simplesmente fazer um comentário baseado em um texto que escrevemos, como “Olá!, ChatGPT !
No final das contas, essas previsões são gerações de textos e pertencem ao tipo de ferramentas de IA que são chamadas: generativas. A qualidade de um LLM é medida de acordo com a sua coerência, precisão e correta contextualização das suas respostas. Essas medições são realizadas por pessoas, desta forma, podem ser identificados seus pontos fortes e fracos.
LLaMA 2
Durante 2023, a Meta anunciou o LLaMA 2 (de agora em diante vou chamá-lo simplesmente de Llama 2), um LLM de código aberto que é a evolução de seu modelo anterior (LLaMA 1), que pode ser usado para criar aplicações para fins comerciais.
As instruções para baixá-lo estão em seu repositório:
 facebookresearch
facebookresearchObserve que você terá que solicitar um link de download que a Meta deverá fornecer a você. Além disso, existem três modelos diferentes de Llama 2, que variam de acordo com o tamanho: 7B, 13B, 70B. (O "B" significa bilhão e refere-se ao número de parâmetros no modelo.) Quanto maior o número de parâmetros em um modelo, melhor será a qualidade da geração do texto.
Porém, o tempo de resposta também aumentará, pois requer maior poder computacional (por isso é aconselhável utilizar uma GPU, favorecendo o paralelismo massivo deste hardware, em vez de uma CPU).
LangChain com Python
LangChain é um framework que nos permite interagir com LLMs de forma fácil e rápida. Que possui duas funcionalidades principais:
- Integração de dados (chamada com reconhecimento de dados): conecta um LLM a outra fonte de dados, por exemplo, todo o texto que um PDF possui. Isso permite a integração.
- Agente: interagir diretamente com o LLM, fazendo perguntas e obtendo respostas em seu próprio ambiente.
Instalação em Python
Para a instalação do LangChain temos duas opções: Pip ou conda.
Usando Pip:
pip install langchainou Conda:
conda install langchain -c conda-forgeCarregando um PDF
Uma possibilidade que o LangChain oferece é possuir diversos utilitários prontos para uso. Por exemplo, carregue um PDF e extraia seu texto para criar pedaços. Um chunk é um fragmento de uma frase que possui alguma relação semântica. Por exemplo:
"Meu cachorrinho, Pole, é muito travesso".
Nessa frase você pode agrupar em três chunks: "Meu cachorrinho" (que se refere ao meu animal de estimação), «Pole» (nome do meu animal de estimação) e “ela é muito travesso” (representa uma característica dele). Desta forma, nos modelos LLM, e em geral na área de processamento de linguagem natural, é conveniente realizar este tipo de fragmentação, pois podem ter significados semânticos diferentes.
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
# solicita al usuario el path del PDF
path = input("PDF path: ")
# carga el PDF en memoria
loader = PyPDFLoader(path)
documents = loader.load()
# Divide el texto del PDF en pequeños chunks de hasta 1000 caracteres
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)Configurando o banco de dados vetorial
Um banco de dados vetorial é um aliado dos LLMs, pois permite armazenar e processar representações numéricas da enorme quantidade de textos que o modelo deve analisar. Além disso, permite-nos manter o contexto histórico das consultas que fazemos a um determinado LLM.
Para este exemplo usaremos o Pinecone que, assim como no upload de PDF, o LangChain fornece uma interface para integrá-lo.
É essencial primeiro criar uma conta no Pinecode para obter a API_KEY. Uma vez dentro do Pinecode, você deve criar o index (que equivale ao BD), onde serão salvas as representações e interações que faremos com o LLM. Tenha em mente que quando você gera o index Ele irá perguntar a dimensão do índice, para isso você pode usar 768 (esse tamanho depende da quantidade de texto que o banco de dados aguenta). Então, uma vez gerado o index, ele irá atribuir a você um ambiente (local) onde seu índice está localizado, não se esqueça de copiá-lo.
Para integrar o Pinecode ao LangChain, o código deve ser o seguinte:
import pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings import HuggingFaceEmbeddings
pinecone.init(api_key='API_KEY', environment='ENTORNO_ASIGNADO')
# Usamos HuggingFace para transformar el texto en vectores numéricos
embeddings = HuggingFaceEmbeddings()
# Configuramos la BD en Pinecode
index_name = "chat-pdf"
index = pinecone.Index(index_name)
vectordb = Pinecone.from_documents(texts, embeddings, index_name=index_name)Carregando o modelo Llama 2
Para carregar o modelo Llama 2, como aconteceu com o carregamento de PDF e Pinecode, LangChain também nos fornece uma interface (que fácil!).
from langchain.llms import LlamaCpp
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path="models/llama-2-13b-chat.ggmlv3.q4_0.bin",
temperature=0.75,
max_tokens=2000,
n_ctx=2048,
n_batch=512,
top_p=1,
callback_manager=callback_manager,
verbose=False,
)Observe que no código acima o modelo Llama 2 13B se encontra na pasta models. E, por sua vez, é necessário ter um objeto CallbackManager para nos permitir gerenciar as respostas retornadas pelo modelo. Por outro lado, para entender detalhadamente cada parâmetro de LlamaCpp recomendo que você leia este link.
Integrando tudo ao LangChain
Agora só falta configurar o LLM no LangChain, para começar a “conversar” com ele.
qa_chain = ConversationalRetrievalChain.from_llm(
llm,
vectordb.as_retriever(search_kwargs={'k': 2}),
return_source_documents=True
)O parâmetro k = 2 significa a quantidade de documentos que nosso banco de dados no Pinecode pode retornar, deixamos em 2, para que a resposta não seja tão longa. Isto não significa que devolva dois parágrafos ou duas palavras, mas tem a ver com os textos que o modelo considera significativos para fornecer uma resposta: e um documento pode conter vários parágrafos.
Interagindo com o PDF
Com isso basta adicionar o código para interagir com o PDF através do nosso LLM, Llama 2.
chat_history = []
while True:
query = input('\nSolicitud/Pregunta: ')
if query.lower() in ["exit", "quit", "q"]:
print('Exiting')
sys.exit()
result = qa_chain({'question': query, 'chat_history': chat_history})
print('Respuesta: ' + result['answer'] + '\n')
chat_history.append((query, result['answer']))A função qa_chain requer o prompt, query, e uma lista chat_history que mantém a história. Então tudo que você precisa fazer é acessar a resposta do modelo no dicionário result.
O tempo de resposta do modelo depende das características do seu hardware.
Resultado
O prompt foi o seguinte: «Hi! Please, give me a summary», ou seja, pedi para a modelo fazer um resumo do PDF.
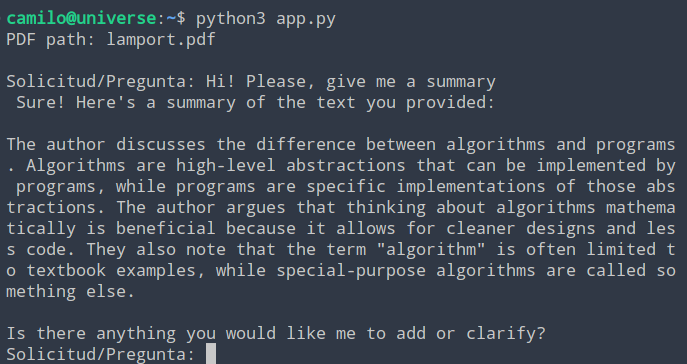
O arquivo lamport.pdf corresponde a um artigo escrito por Leslie Lamport. E tem a estrutura típica de um artigo científico. E, por se tratar de um artigo que já li, posso dizer que o resumo é bastante bom. E abre a oportunidade de fazer muitas outras coisas interessantes.
Conclusão
Neste artigo vimos como LangChain pode facilitar o uso de um LLM, como o Llama 2, usando Python. Além disso, sua flexibilidade de uso ficou evidente pela integração com outras ferramentas, como a base de dados vetoriais Pinecode, e pelo upload de um PDF e extração do texto.
O que se vê neste artigo é apenas um vislumbre das capacidades do LangChain, já que possui muitas outras integrações e, além disso, permite que seja utilizado —através dos plugins— com outros modelos como ChatGPT.
Referências
Para continuar se aprofundando no LangChain, recomendo visitar o link a seguir.

E se você está curioso para saber como funciona o LLM Llama 2, teoricamente, então visite o artigo a seguir.


A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.