Guia intermediário Node.Js


Antes de começarmos, gostaria de ressaltar que este é o segundo artigo de uma série completa composta por três partes. Se você perdeu a primeira parte, não se preocupe! Você pode acessá-la em nosso blog e garantir uma base sólida antes de mergulharmos nas técnicas intermediárias do Node.js.

Então, por que você deve se interessar por essa linguagem em nível intermediário?
Bem, o Node.js é amplamente utilizado para desenvolvimento de aplicativos de servidor, permitindo que você crie soluções escaláveis e de alto desempenho. Com sua arquitetura baseada em eventos e sua capacidade de executar código JavaScript tanto no lado do cliente quanto no lado do servidor, o Node.js se tornou uma escolha popular para muitos desenvolvedores.
Lendo esse artigo que citei anteriormente você terá acesso a temas como: configuração do ambiente em vários sistemas operacionais, pontos positivos em usar o Node.js, e a sintaxe básica da linguagem.
Neste guia intermediário, abordaremos tópicos como manipulação avançada de arquivos com o módulo “fs”, utilização de Banco de Dados e Streaming de dados eficiente.
Com os tópicos abaixo você aprenderá a tirar o máximo proveito do Node.js e aprimorar suas habilidades de programação.
Módulos e Habilidades intermediárias de Node.js
Manipulação avançada de arquivos e diretórios com o módulo "fs".
A manipulação avançada de arquivos e diretórios é uma tarefa essencial no desenvolvimento de aplicativos com Node.js. O módulo "fs" (file system) é uma das principais ferramentas disponíveis para lidar com operações relacionadas a arquivos e diretórios. Neste guia intermediário, vamos explorar as funcionalidades avançadas do módulo "fs" e aprender como utilizá-lo de forma eficiente em nossos projetos.
O primeiro passo é garantir que o módulo "fs" esteja instalado em seu ambiente Node.js. Felizmente, o "fs" faz parte dos módulos principais do Node.js, então você não precisa se preocupar em instalá-lo separadamente.
Você pode simplesmente importá-lo em seu código da seguinte maneira:

Agora que temos o módulo "fs" disponível, podemos começar a explorar suas funcionalidades.
Para ler um arquivo, podemos usar o método fs.readFile(). Ele recebe o caminho para o arquivo que queremos ler e um “callback” que será invocado quando a operação for concluída. O “callback” recebe dois parâmetros: um erro, caso ocorra, e os dados lidos do arquivo.

Da mesma forma, para escrever em um arquivo, podemos utilizar o método fs.writeFile(). Ele recebe o caminho para o arquivo que queremos escrever e os dados que desejamos gravar. Assim como no fs.readFile(), também podemos passar um callback para lidar com possíveis erros.

Além das operações básicas de leitura e gravação, o módulo "fs" também oferece recursos avançados, como renomear ou mover arquivos, criar e remover diretórios, entre outros.
Vamos explorar algumas dessas funcionalidades agora!
Para renomear um arquivo, podemos utilizar o método fs.rename(). Ele recebe o caminho do arquivo atual e o novo nome que queremos atribuir a ele. Essa operação é síncrona e não requer um callback.

Para criar um diretório, utilizamos o método fs.mkdir(). Ele recebe o caminho para o novo diretório que queremos criar e também pode receber um callback para lidar com erros.

E se precisarmos remover um arquivo ou diretório? Para remover um arquivo, utilizamos o método fs.unlink(). Para remover um diretório vazio, utilizamos o método fs.rmdir(). Ambas as operações também podem receber um callback para lidar com erros.

Agora que você tem um conhecimento intermediário sobre a manipulação avançada de arquivos e diretórios com o módulo "fs", você está pronto para aplicar esses conceitos em seus próprios projetos, além disso, tal conhecimento também vai te ajudar a agilizar seu trabalho com o Node.js.
Trabalhando com bancos de dados utilizando o Node.js, incluindo bancos de dados relacionais e NoSQL.
Trabalhar com bancos de dados é uma parte fundamental do desenvolvimento de aplicativos robustos e escaláveis. O Node.js oferece suporte para uma variedade de bancos de dados, tanto relacionais quanto NoSQL. Neste guia, vamos explorar como utilizar o Node.js para interagir com esses dois tipos de bancos de dados, fornecendo a você as ferramentas necessárias para armazenar e recuperar dados de forma eficiente.
Começando com bancos de dados relacionais, o Node.js oferece várias bibliotecas populares para se conectar e interagir com bancos de dados como MySQL, PostgreSQL e SQLite. Uma das bibliotecas mais comuns é o "node-mysql", que permite estabelecer conexões com bancos de dados MySQL e executar consultas SQL de maneira simples e eficaz.
Assim, vamos explorar os bancos de dados SQL.
Para começar, você precisará instalar a biblioteca "node-mysql" através do npm (gerenciador de pacotes do Node.js). Depois de instalada, você pode importar a biblioteca e configurar uma conexão com seu banco de dados da seguinte maneira:

Com a conexão estabelecida, você pode executar consultas SQL para inserir, atualizar, recuperar e excluir dados do banco de dados. Aqui está um exemplo simples de como executar uma consulta SELECT para recuperar dados de uma tabela:

Agora, vamos explorar os bancos de dados NoSQL.
No contexto do Node.js, o MongoDB é uma opção popular para bancos de dados NoSQL devido à sua flexibilidade e facilidade de uso. Para interagir com o MongoDB, você pode utilizar a biblioteca "mongoose", que fornece uma camada de abstração para simplificar a comunicação entre o Node.js e o MongoDB.
Da mesma forma que com o "node-mysql", você precisará instalar o "mongoose" via npm e importá-lo em seu código. Em seguida, você pode estabelecer uma conexão com o MongoDB e definir um esquema para seus dados.
Veja um exemplo básico abaixo:

Agora você pode usar o "Model" para executar operações de CRUD (criação, leitura, atualização e exclusão) no MongoDB. Aqui está um exemplo simples de como criar um novo documento:
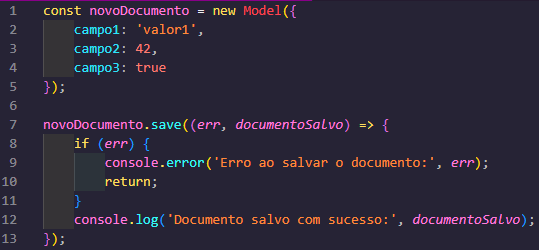
Com essas informações, você está preparado para trabalhar com bancos de dados utilizando o Node.js. Lembre-se de adaptar as configurações e exemplos ao banco de dados específico que você está utilizando.
Utilização de streaming de dados para processar grandes volumes de informações de forma eficiente.
A utilização de streaming de dados é uma técnica poderosa para processar grandes volumes de informações de forma eficiente no Node.js. Ao trabalhar com dados em tempo real, como leitura de arquivos grandes ou transmissão de dados pela rede, o streaming permite processar os dados à medida que eles são recebidos ou lidos, em vez de esperar que o processo seja concluído para começar a manipulá-los.
O Node.js fornece a classe "Stream" como parte de seu módulo "stream", que permite trabalhar com streaming de dados. Existem dois tipos principais de streams: Readable e Writable. Um stream Readable é usado para ler dados de uma fonte, como um arquivo ou uma requisição HTTP, enquanto um stream Writable é usado para gravar dados em um destino, como um arquivo ou uma resposta HTTP.
Suponha que você queira ler um arquivo grande e processar os dados linha por linha. Podemos criar um stream Readable para ler o arquivo e receber eventos de dados à medida que ele é lido.
Veja um exemplo abaixo:

Nesse exemplo, utilizamos o método createReadStream() do módulo "fs" para criar um stream Readable para ler o arquivo. Em seguida, registramos um callback para o evento 'data', que é disparado sempre que um pedaço de dados é lido. Dentro desse callback, processamos cada linha do arquivo. Por fim, registramos um callback para o evento 'end', que é disparado quando todo o arquivo foi lido.
Agora, vamos abordar o streaming de dados de escrita. Suponha que você queira criar um arquivo grande com base em dados gerados dinamicamente. Podemos criar um stream Writable para escrever os dados no arquivo à medida que eles são gerados.
Veja um exemplo abaixo:

Nesse exemplo, utilizamos o método createWriteStream() do módulo "fs" para criar um stream Writable para escrever no arquivo. Em seguida, usamos um loop para gerar os dados e escrevê-los no stream por meio do método write(). Por fim, chamamos o método end() para sinalizar o término da escrita.
Utilizar o streaming de dados no Node.js é uma abordagem eficiente para processar grandes volumes de informações. Ao utilizar streams, você pode economizar memória, pois não precisa carregar todos os dados na memória de uma vez. Em vez disso, você pode processar os dados à medida que eles chegam, tornando seu aplicativo mais eficiente e escalável.
Lembre-se de explorar as várias funcionalidades do streaming de dados no Node.js, como o encadeamento de vários streams, o uso de” transform” streams para processar dados em tempo real e o tratamento adequado de eventos e erros.

Com essas informações, você está pronto para utilizar o streaming de dados para processar grandes volumes de informações de forma eficiente em seus projetos Node.js. Aproveite os benefícios do streaming e crie aplicativos que lidem com dados de maneira rápida, eficiente e escalável.
Agora que você já explorou alguns tópicos essenciais em um nível intermediário, está pronto para avançar para o próximo estágio do nosso guia de Node.js. No próximo artigo, mergulharemos em conceitos mais avançados e abordaremos técnicas que elevarão suas habilidades a um novo patamar.
Assim encerramos aqui o guia de hoje!
À medida que avançamos para a próxima parte desta série, tenha certeza de estar preparado para explorar tópicos avançados e descobrir os segredos do desenvolvimento Node.js de alto nível. O que estão achando dos guias recentes de Node.js? Conte-me nos comentários do post.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.