Introdução às Aggregation Operations do MongoDB


Hoje, muitas startups preferem o MongoDB como banco de dados devido à grande flexibilidade que ele oferece em suas seções de modelagem e/ou consulta.
Neste artigo aprenderemos mais sobre uma das ferramentas mais promissoras pela sua utilidade no processamento de documentos de uma ou múltiplas coleções: as operações de agregação.
Ressalta-se que você não precisará baixar ou instalar nada, mas poderá praticar em um playground online presente neste link para que possamos focar no que realmente importa: Colocar em prática o que aprendemos neste artigo!
Mas antes de começar a trabalhar você precisa entender alguns conceitos.

O que são as Aggregation Operations?
São operações que permitem que processos sejam aplicados a vários documentos. Isso pode ser feito usando etapas (Aggregation Pipelines) ou funções de propósito único, mas neste artigo daremos ênfase especial aos Aggregation Pipelines.
O que são as Aggregation Pipelines?
São sequências de etapas que permitem realizar diferentes processos nos documentos de entrada. Cada etapa processa os documentos e envia o resultado para a próxima etapa, podemos ver com mais detalhes no diagrama a seguir:

Como indica o diagrama acima, pode haver um número n de estágios. Ao modificar a estrutura dos documentos dentro de um estágio, nenhuma informação armazenada no banco de dados será modificada, a menos que sejam usados os estágios $merge ou $out.
Existem diferentes tipos de etapas, cada uma com uma finalidade específica como adicionar ou remover propriedades de documentos, obter informações de outras coleções, etc.
Nesta ocasião vamos nos concentrar nas seguintes etapas:
- $match
- $project
Antes de começar, teremos que nos familiarizar um pouco com a ferramenta que utilizaremos para praticar. Para começar, vamos clicar neste link.
Ao entrar, deverá redirecioná-los para uma página como a seguinte, com o playground pronto para funcionar.
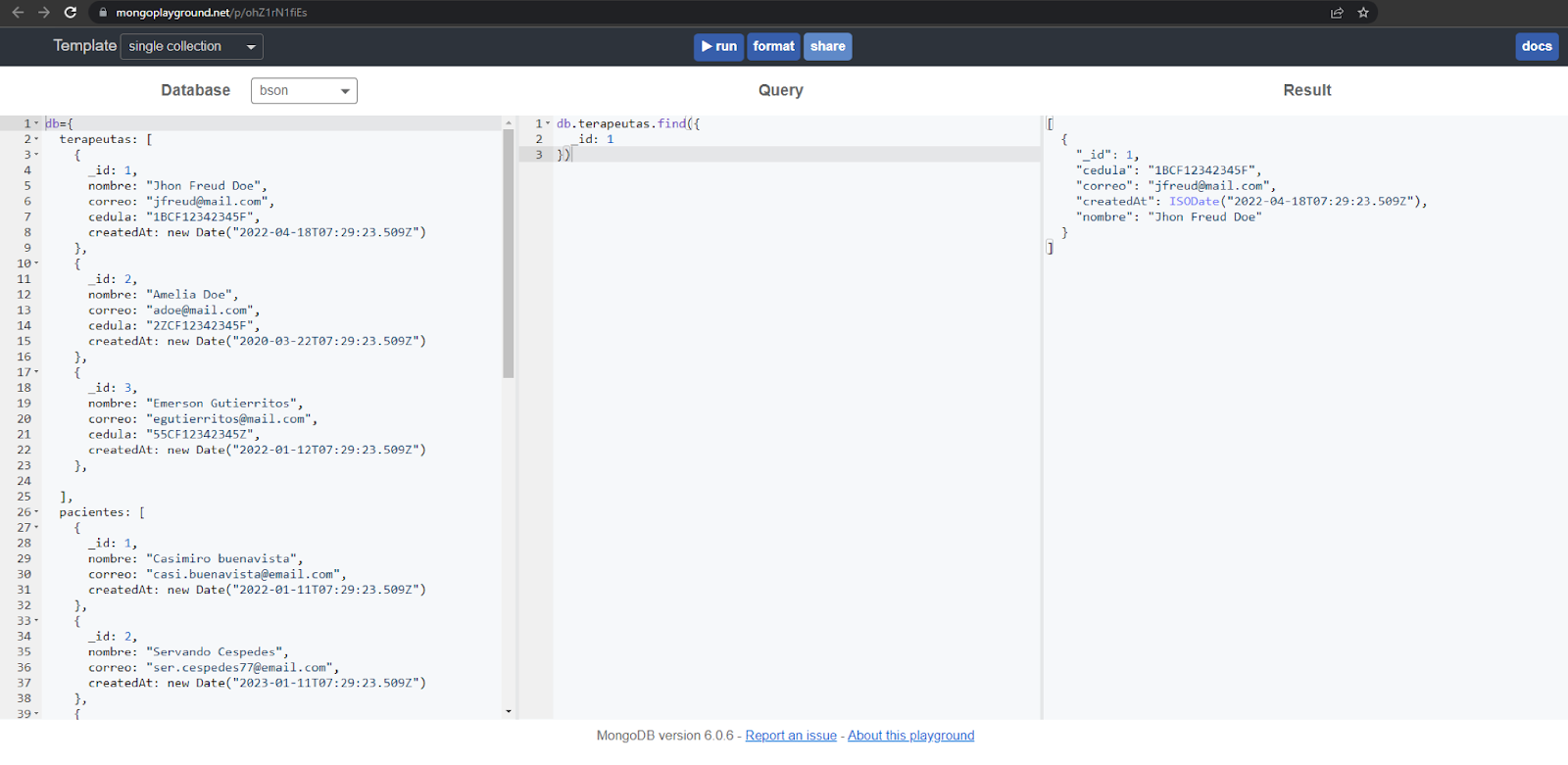
Caso a seção Database não tenha conteúdo, é necessário colar o seguinte código:
O código anterior é um banco de dados de um centro terapêutico fictício e servirá de conteúdo para trabalhar com os exemplos que veremos mais adiante.
O site em que trabalharemos é um playground que utiliza MongoDB Shell (mongosh) para executar comandos, não inclui tudo o que o mongosh pode fazer, mas nos permite usar aggregations sem problemas.
Vamos falar um pouco sobre a interface, que inclui uma seção para o código do banco de dados, o código da consulta e outra para exibição dos resultados. Também inclui pequenos botões na parte superior que nos permitem executar, formatar, compartilhar e visualizar a documentação do mesmo site. Os mais importantes são o botão executar e formatar e, para nossa sorte, é possível ativá-los com atalhos, que são Ctrl(Cmd) + Enter para executar e Ctrl(Cmd) + s para formatar.
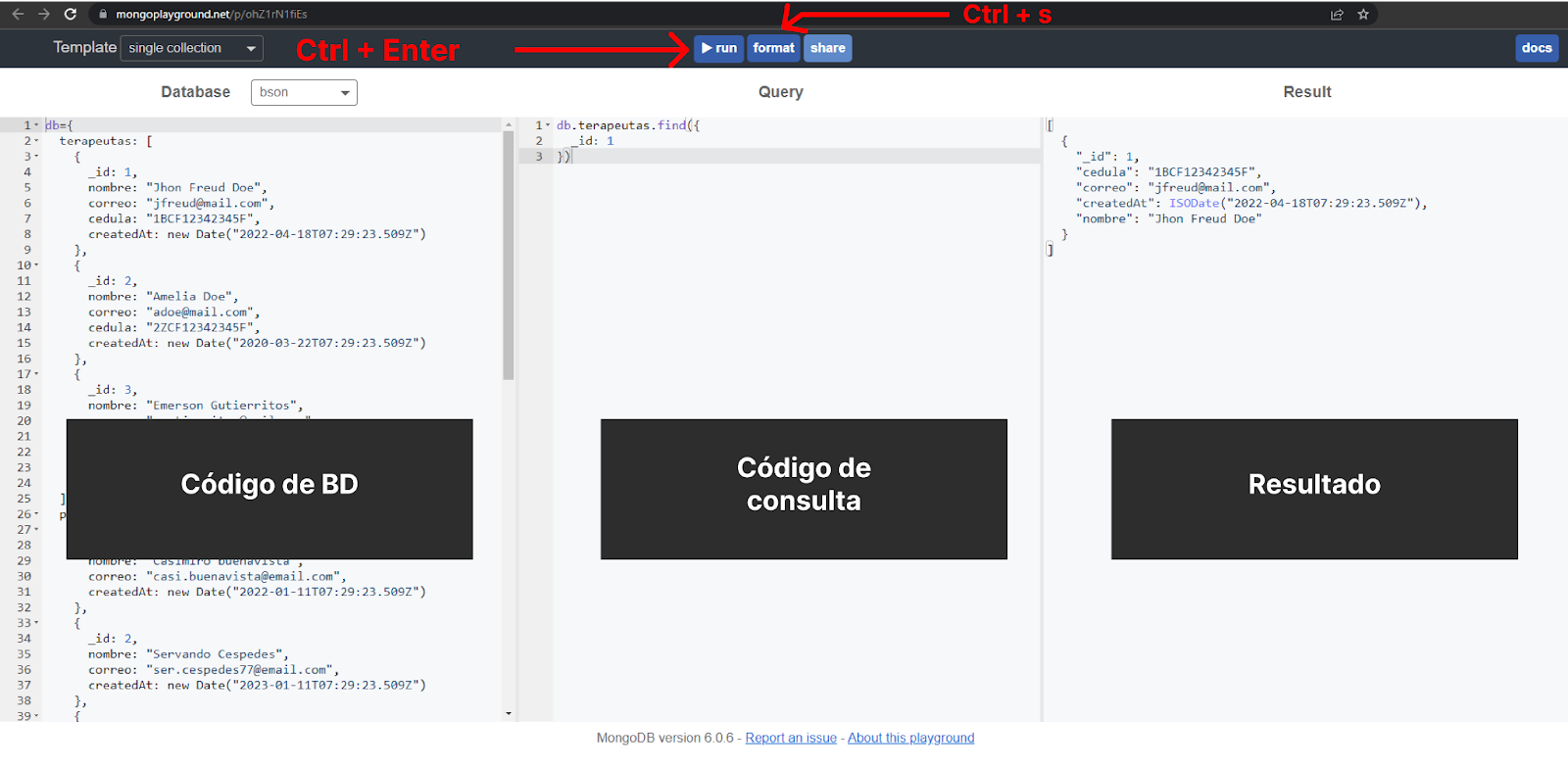
Uma vez compreendida a interface, podemos começar com nosso primeiro Aggregation pipelines colocando o comando que servirá para conter cada uma das etapas que iremos executar.
Cada estágio é um objeto que contém uma chave indicando seu tipo. Por sua vez, a chave deve conter um objeto com a configuração do estágio.
Após esta breve introdução à estrutura de um pipeline, é hora de começar com os exemplos das etapas indicadas acima.
$match
É o find das etapas, com a qual você pode adicionar condições e parâmetros para encontrar documentos que as atendam.
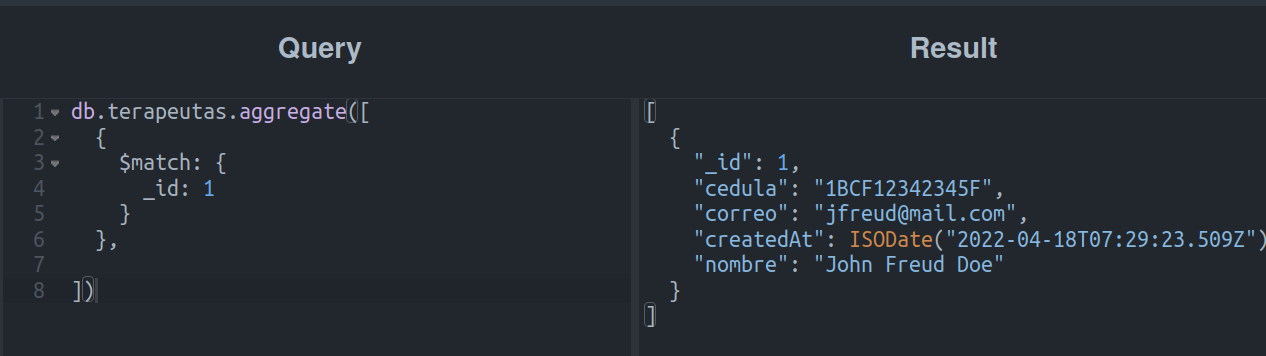
O primeiro e mais simples exemplo de como usá-lo seria o seguinte:
Usando o exemplo acima, podemos filtrar os terapeutas com o _id “1”. Quando o executamos em nosso playground, podemos ver o seguinte resultado:
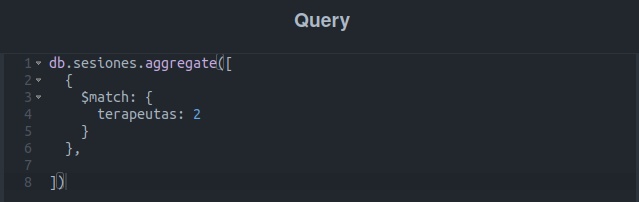
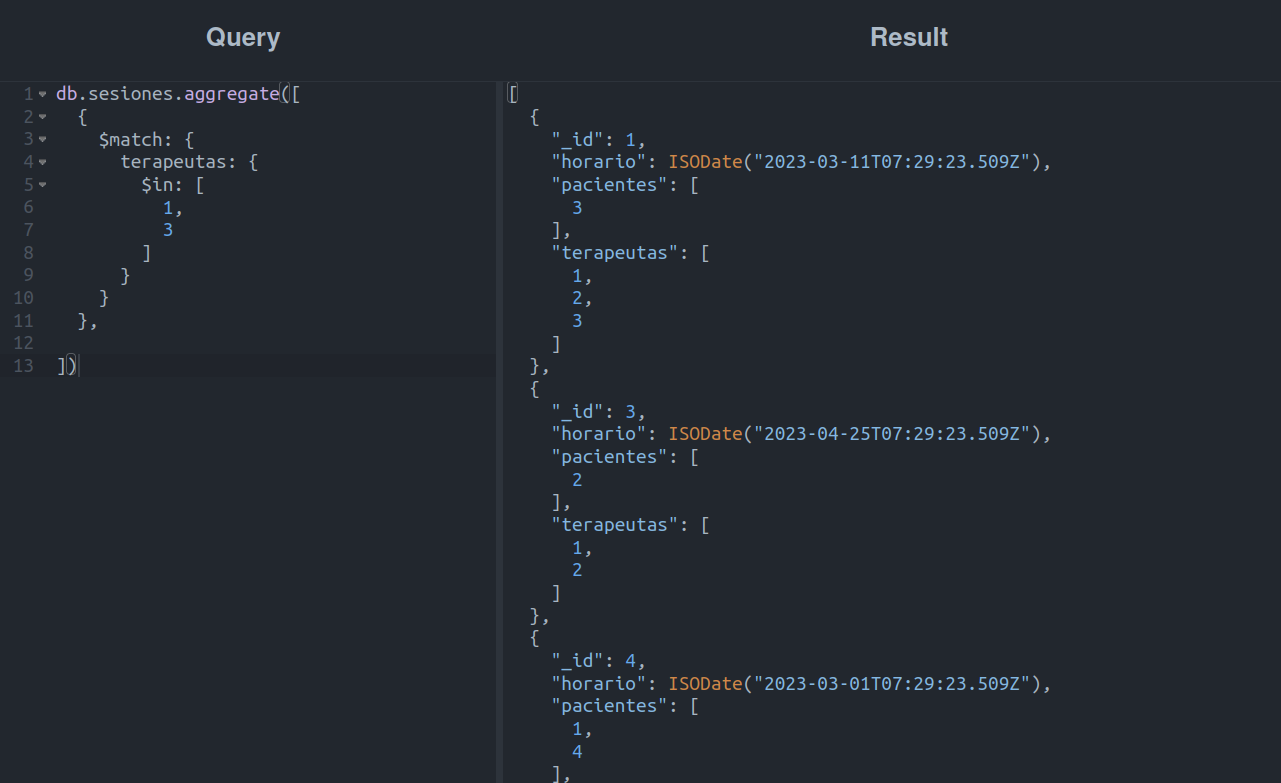
Agora algo mais interessante: buscaremos todas as sessões em que a terapeuta Amelia Doe estará presente:
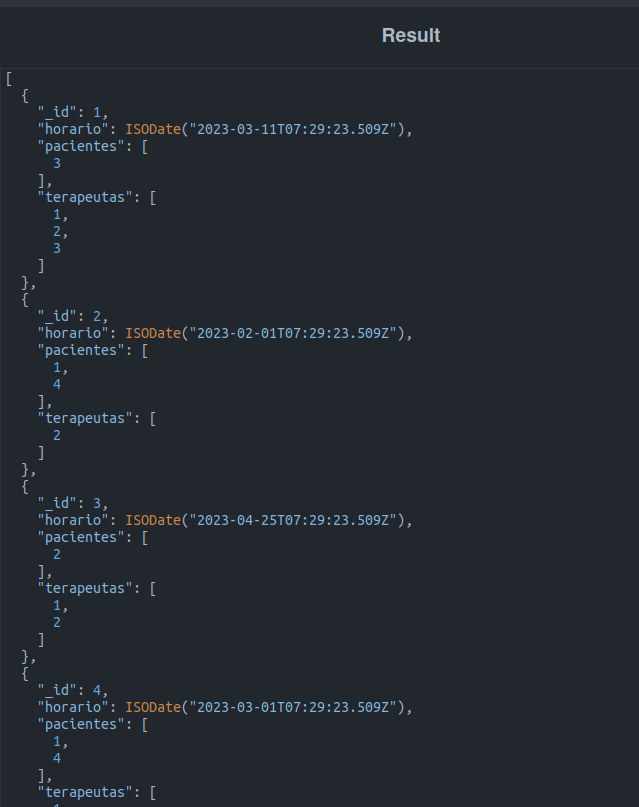
Agora vamos procurar as sessões onde mais de um paciente comparecerá:
Nesta consulta, existem 3 novos elementos. Iremos conhecê-los com mais detalhes após executar o comando.
Como podemos notar, agora temos 3 novas peças no jogo:
- $expr, que permite avaliar expressões com condicionais. Isto permite-nos filtrar e descartar todos os documentos que não cumpram esta expressão.
- $gt, útil para comparar valores, de modo que retornará um valor verdadeiro sempre que a expressão A for maior que a expressão B.
- $size, retorna a contagem de elementos dentro de um array, que pode ser um literal ou um campo da coleção.
Antes de continuar gostaria de mencionar os “irmãos” do $gt, eles são muito úteis e baseiam-se no mesmo princípio comparando as expressões A e B:
- $lt, o conhecido lower than, menor que ou <, para amigos.
- $lte, semelhante ao anterior, para comparar valores menores ou iguais.
- $gte, semelhante ao que usamos no exemplo, mas para valores maiores ou iguais.
- $eq, para comparar se os valores são idênticos.
- $ne, é verdadeiro sempre que ambas as expressões são diferentes.
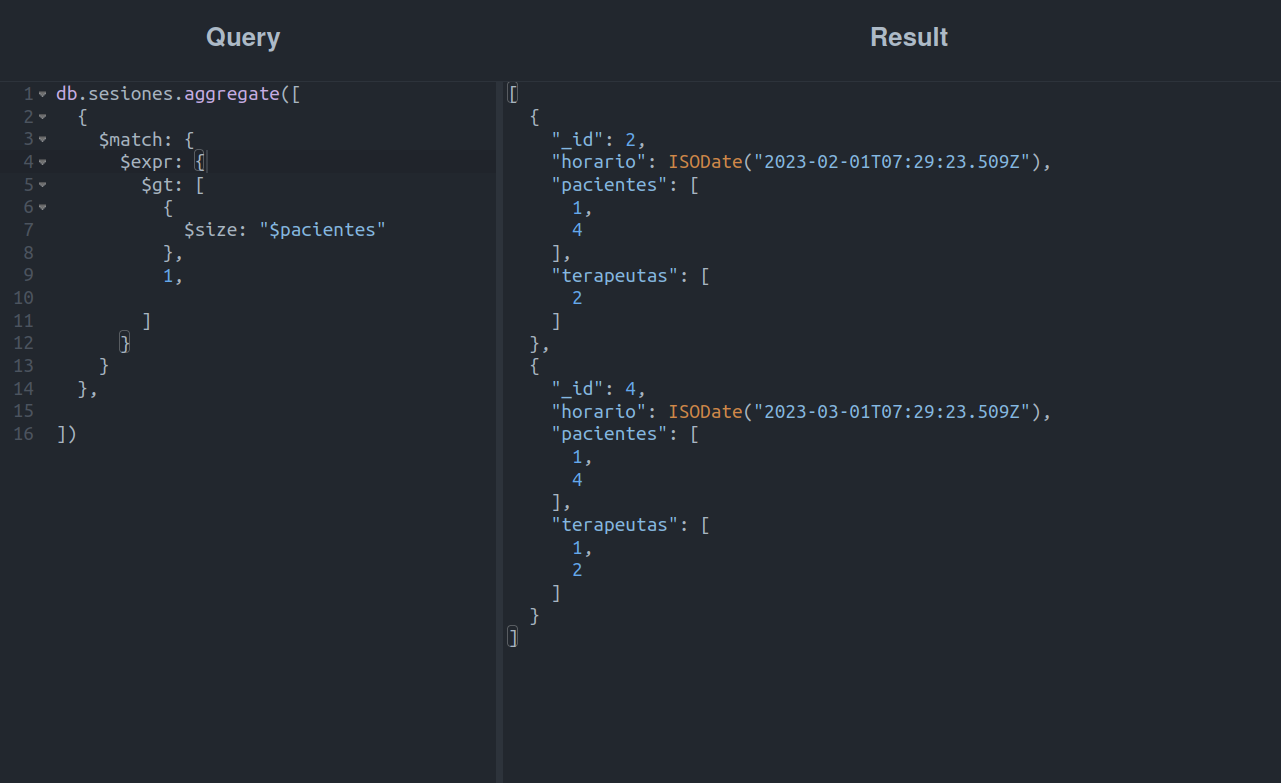
Vamos ao último exemplo desta etapa, buscando sessões que incluam os terapeutas John Freud Doe ou Zé Ninguém.
Se o seu objetivo é filtrar documentos por parâmetro usando um array, $in é o operador que você precisa, pois permite filtrar documentos desde que o campo especificado contenha ou seja igual a um dos elementos especificados na lista.
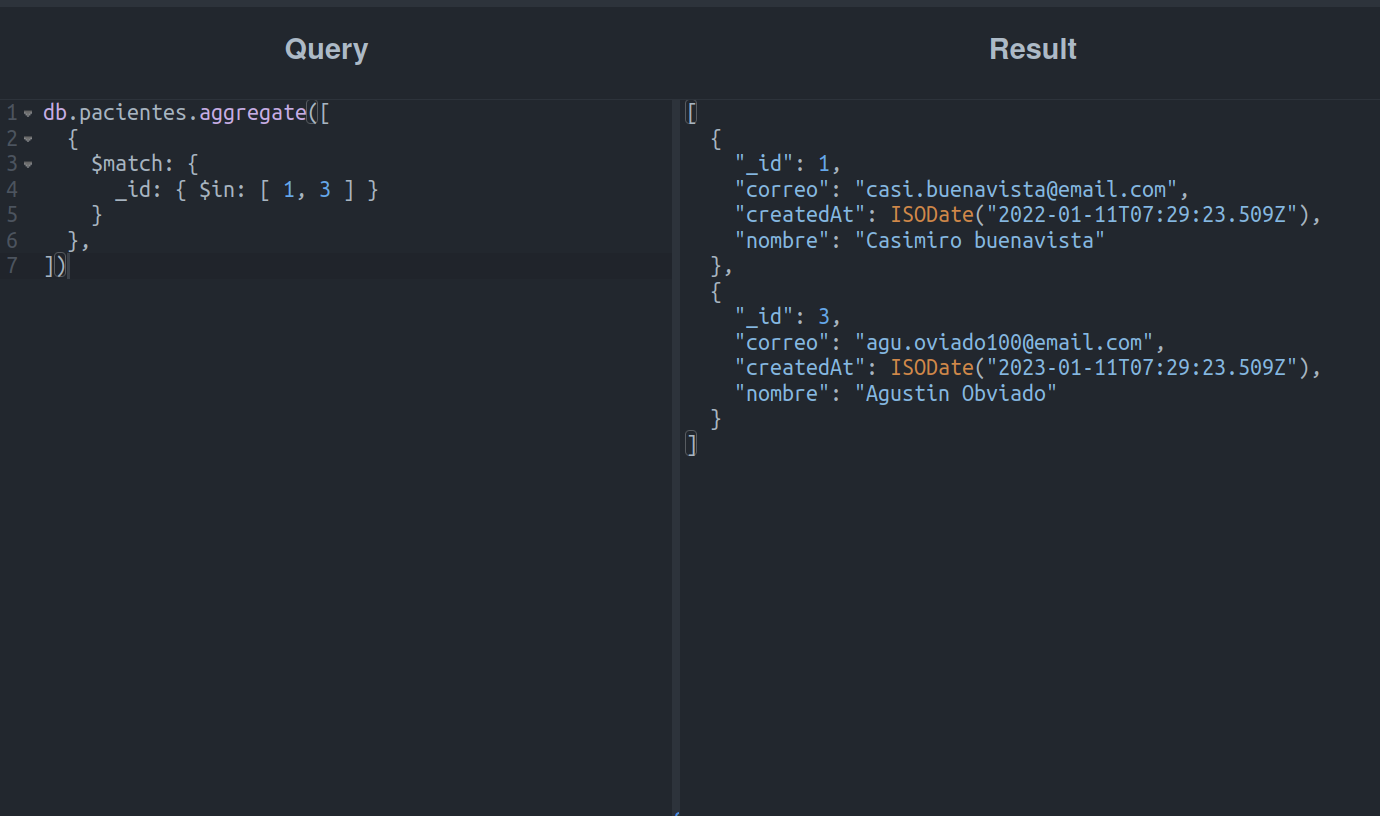
No exemplo anterior, um array foi comparado a um campo do mesmo tipo, mas pode ser utilizado quando o conteúdo do campo for um valor único, por exemplo:
Esta operação obterá os pacientes desde que o campo _id seja especificado na lista de operadores $in.
$project
Dentro desta etapa podemos modificar os valores de saída, seja adicionando campos, gerando-os com valores calculados ou até mesmo fazendo listas com os campos do documento.
Vamos fazer uma consulta que obtenha apenas o nome e email de todos os terapeutas:
Como pode ser visto no código, para indicar quais campos o resultado deve conter, basta escrever o nome do que queremos e atribuir 1 como valor. Em teoria deveria ser assim, pois ao executá-lo podemos perceber que temos um intruso:
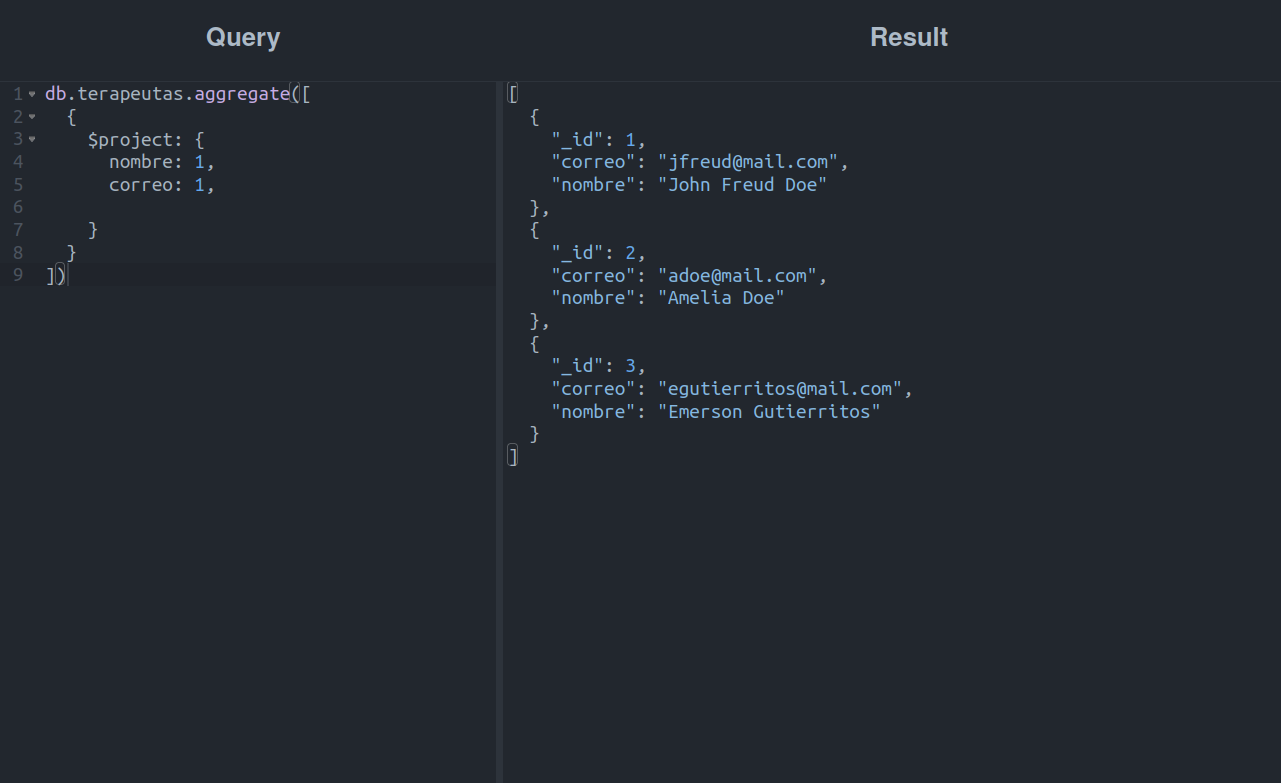
De fato. O _id dos terapeutas vazou!
Este é um comportamento normal, pois apesar de ter estabelecido uma lista com os campos que queremos exibir, a etapa $project sempre retornará o campo _id junto com os campos por nós especificados, salvo indicação em contrário:
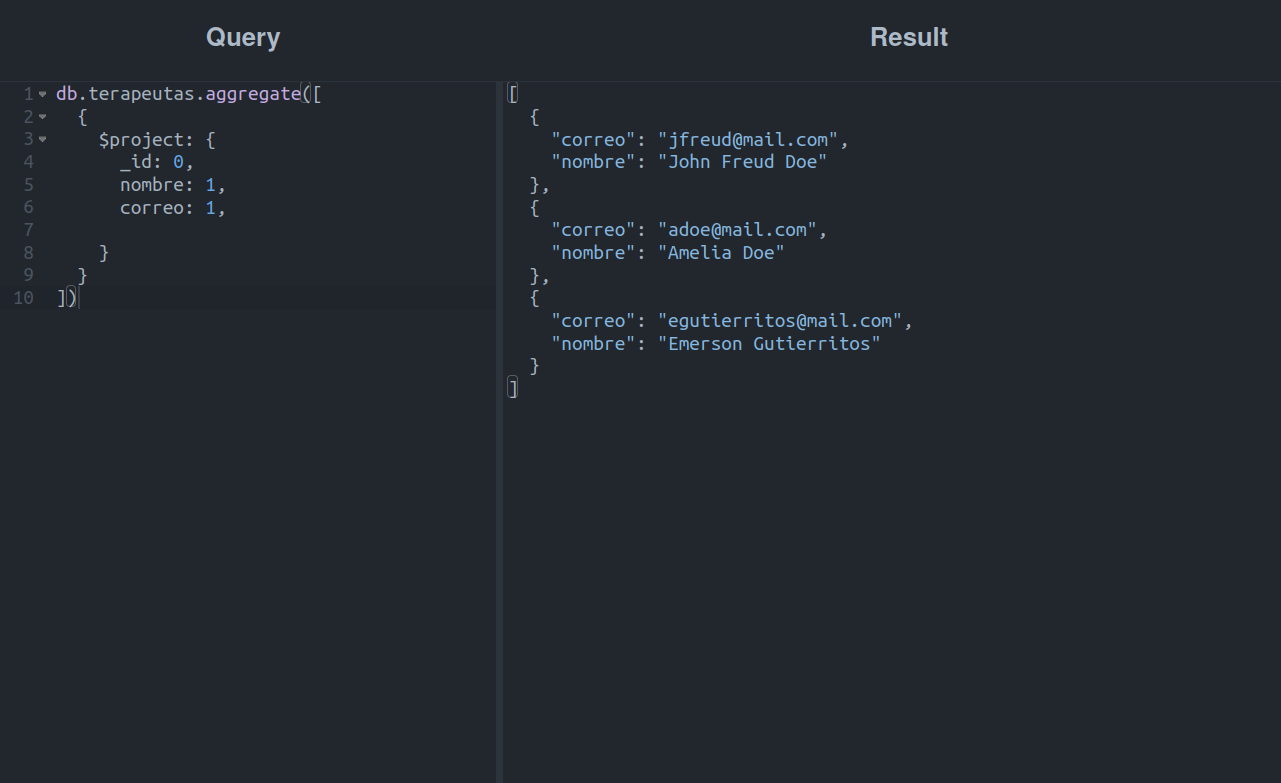
Muito melhor, não é?
Ok, agora vamos tentar pegar os terapeutas, mas sem os campos createdAt e _id:
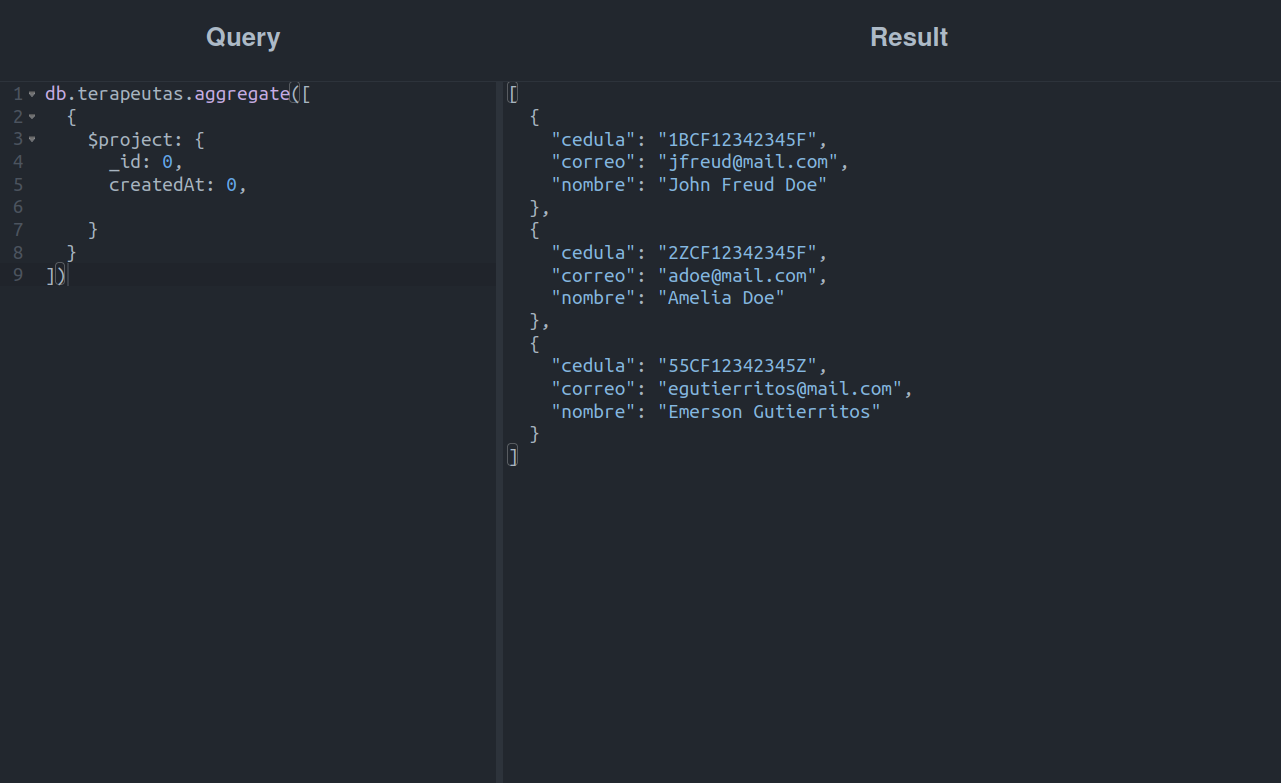
Aqui podemos ver que a etapa $project funcionou como uma lista e mostrou apenas os campos que não marcamos com 0.
Vamos parar um pouco e pensar: será possível incluir um campo e excluir outro na mesma etapa? O que aconteceria se tentássemos?
Calma, vamos da reflexão à empírica ou, como se costuma dizer em minhas terras, “que troveje o que troveja”.
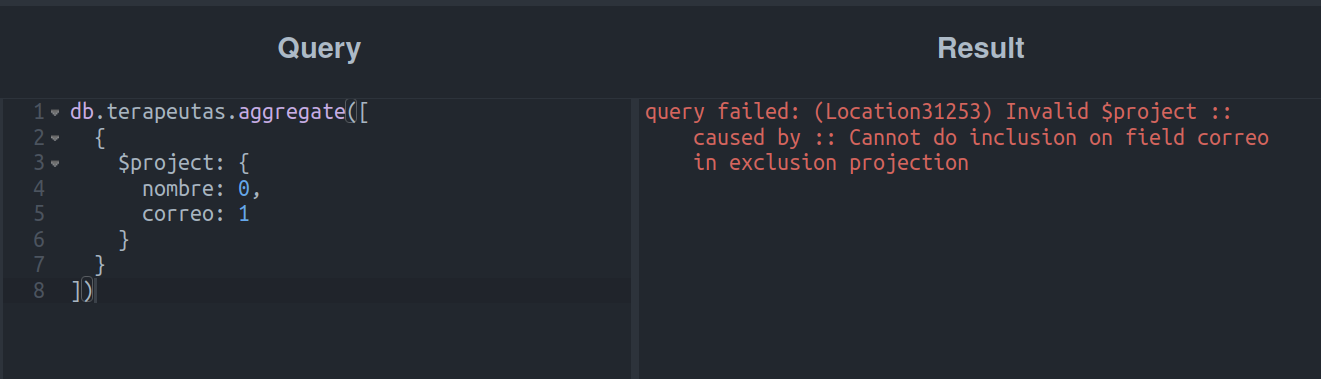
Okay, um erro…
E se tentarmos inverter os valores de nome e email?
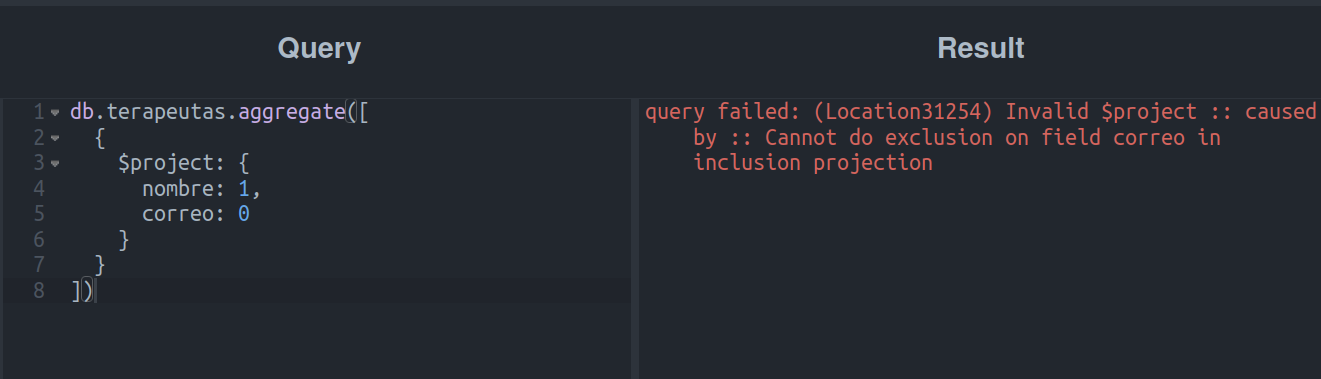
O resultado não parece ter melhorado em nada.
Vejamos, em poucas palavras, o Tio Mongo está nos dizendo que não podemos fazer inclusões e exclusões ao mesmo tempo.
Tomando os exemplos anteriores, podemos dizer que a única forma de misturar uma exclusão e uma inclusão é quando a exclusão é para o campo _id.
Vamos tentar algo mais interessante: vamos pegar a lista de sessões onde os terapeutas Amelia Doe e John Freud Doe atendem juntos na mesma sessão, no resultado mostraremos apenas os campos _id e horário. Também adicionaremos um novo campo chamado type, que conterá o valor individual caso apenas um paciente compareça à sessão. Em vez disso, o valor do grupo será utilizado se houver dois pacientes ou mais.
Vamos decompor um pouco o problema, aqui precisaremos:
- Filtrar com base no ID do terapeuta.
- Mostrar campos horario e _id.
- Adicione um campo chamado type que terá valores variáveis, dependendo do número de pacientes.
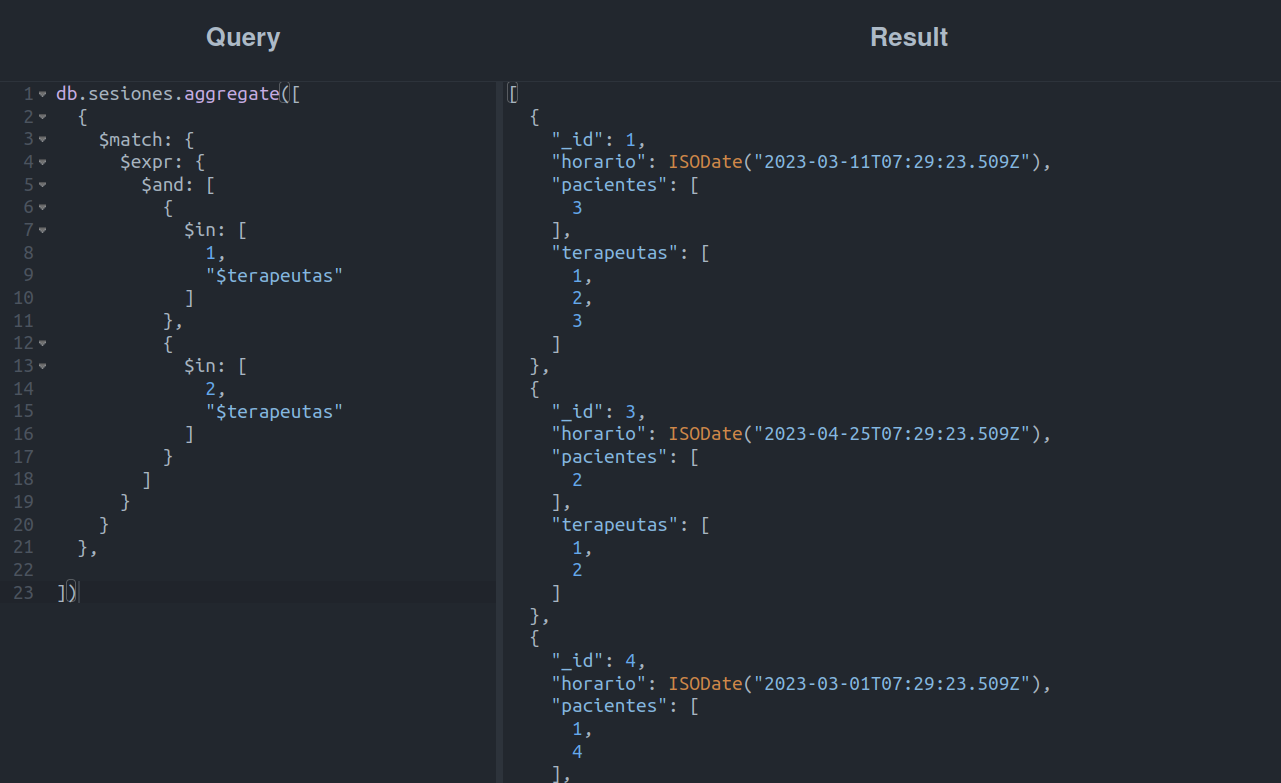
Vamos fazer isso em etapas: vamos começar com o filtro dos terapeutas com uma etapa $match e alguns novos conceitos:
Aqui temos alguns novos detalhes:
- $and, esta expressão permite que múltiplas expressões sejam avaliadas. Para que seja verdade, todas as expressões dentro dele devem ser verdadeiras.
- $in, tínhamos visto isso em sua versão de operador. Neste exemplo é usado como uma expressão, que será verdadeira se o valor A for encontrado no array B.
Usando essas duas ferramentas podemos chegar ao seguinte resultado:
Concluída a etapa de filtragem, é necessário adicionar uma segunda etapa para mostrar apenas o campo horário:

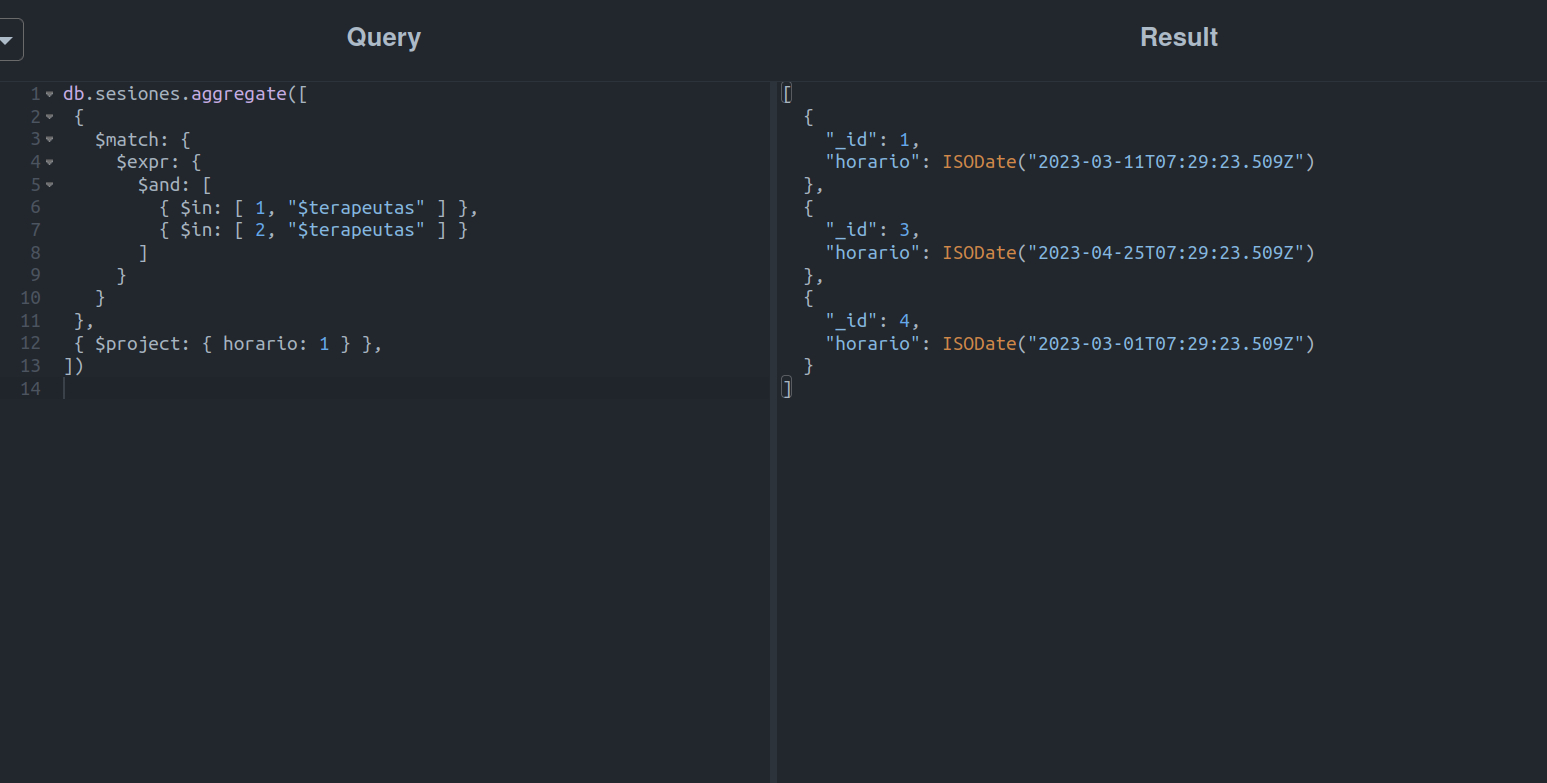
Até este ponto, conseguimos satisfazer o primeiro e o segundo pontos dos requisitos de consulta. Resta adicionar o campo extra que terá um valor baseado na quantidade de pacientes da sessão, o que é feito da seguinte forma:

Para resolver este caso, foram utilizados operadores vistos anteriormente e algo novo:
- $cond, Literalmente, é um operador ternário que nos permite obter um valor A ou B, dependendo se a condicional C está correta ou não.

Utilizando a expressão $cond em combinação com $gt e $size, obteremos o número de pacientes e verificaremos se são maiores que 1.
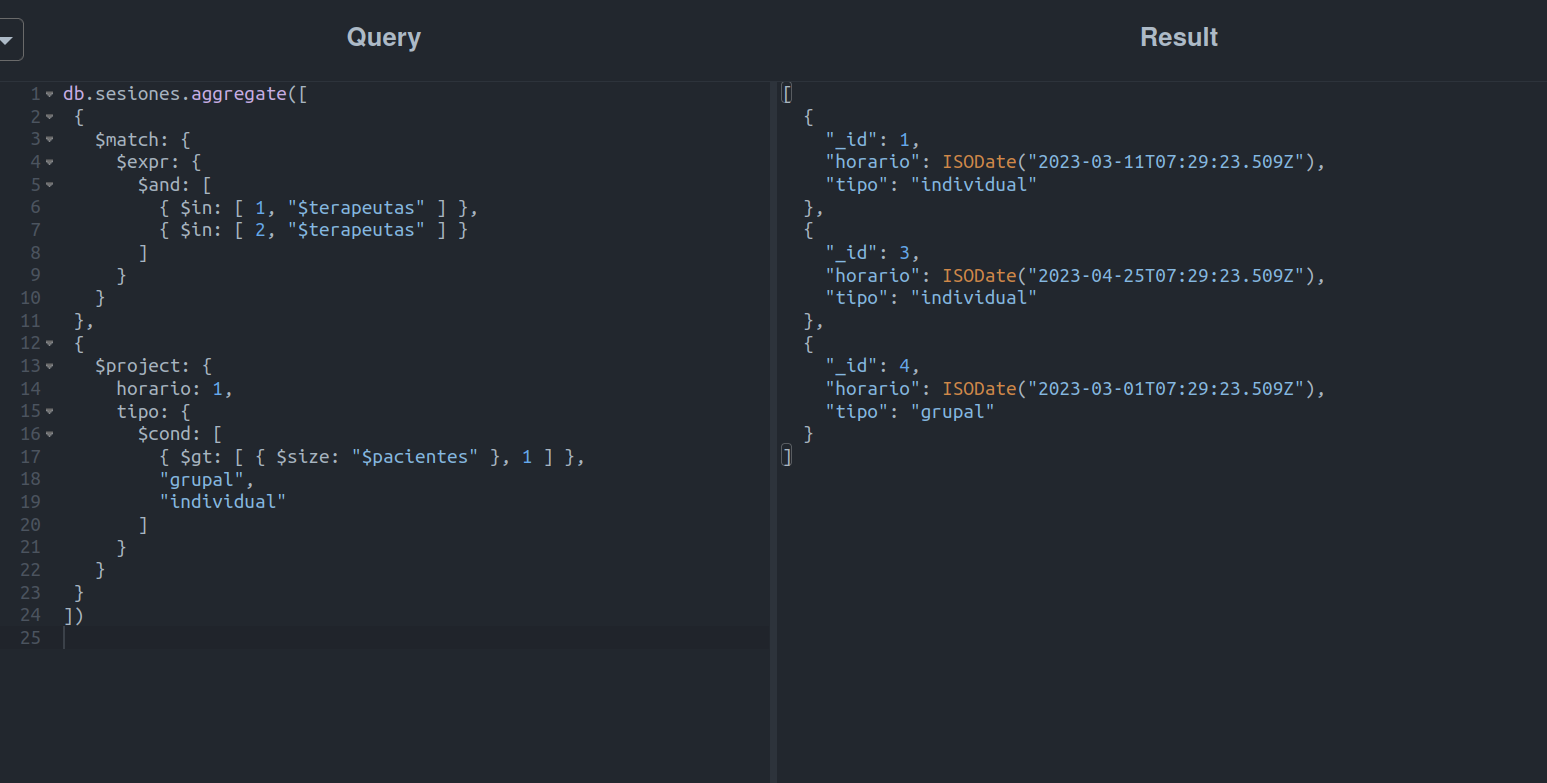
E pronto!
Temos uma consulta que atende a todos os requisitos propostos e, melhor ainda, noções básicas de funcionamento dos aggregates (operações de agregação) e alguns operadores super úteis para filtrar e processar os documentos resultantes.
Além dos 2 tipos de etapas e diferentes operadores utilizados neste artigo, existem muitos mais que podemos encontrar diretamente na documentação do MongoDB.

Como contribuição final, se este artigo conseguiu despertar seu interesse e você quer saber o que seria um bom passo para continuar, recomendo aprender mais sobre a etapa $lookup, pois ela é utilizada para buscar informações em outras coleções utilizando dados dos documentos de entrada. Além de gerenciar um pipeline interno para processar os dados resultantes, é simplesmente uma ferramenta necessária e bastante poderosa.
Todo sucesso em seus projetos! Saudações!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.