Process Mining com PM4PY


Tenho certeza de que você se identificaria com o Process Mining se pensar em como usa aplicativos ou sites em sua vida diária.
Por exemplo, imagine quando você compra produtos online ou reserva viagens: você sempre gera dados que podem ser analisados com Process Mining. As empresas o usam para melhorar a experiência do usuário, o que significa que as alterações feitas nos processos podem ter um impacto direto em como pessoas como você ou eu interagimos com aplicativos e sites.
Outro exemplo: se uma empresa melhorar seu processo de compra online usando o Process Mining, os clientes podem se sentir mais satisfeitos com a experiência e ter mais vontade de comprar nessa loja novamente.
Para dar alguns exemplos mais específicos, existem muitas empresas conhecidas que usam essa técnica para melhorar seus processos. Aqui estão alguns:
- Siemens: Ela usou o Process Mining para analisar seu processo de produção de motores elétricos e obteve uma melhoria de 25% no processo de produção.
- Volkswagen: Por meio do Process Mining, analisou o processo de montagem de seus veículos e otimizou a eficiência da cadeia de suprimentos.
- KLM Royal Dutch Airlines: Graças ao Process Mining, ele analisou o processo de carregamento e reduziu em 50% os atrasos no envio de bagagens.

O que é Process Mining?
Process Mining ou Mineração de Processos é uma técnica que analisa processos de negócios registrando eventos em bancos de dados. Basicamente, trata-se de pegar os dados que são gerados no dia a dia de uma empresa como transações, cliques, interações com clientes e fornecedores, entre outros.
Esses dados são analisados para entender como os processos fluem e quais são os problemas (bottlenecks) que podem afetar a eficiência do negócio. Com o auxílio de ferramentas especializadas, o Process Mining permite visualizar os processos graficamente e obter informações valiosas que melhoram a tomada de decisão. Isso é valioso porque podemos otimizar processos para obter maior eficiência e lucratividade na empresa.
Quais casos de uso tem?
Algumas das aplicações mais comuns são:
- Melhoria de processos: é usado para identificar atrasos e outras ineficiências nos processos de negócios, a fim de otimizá-los e melhorá-los.
- Conformidade normativa: as empresas estão sujeitas a regulamentos e regulamentos que devem cumprir. Process Mining é usado para monitorar e auditar processos de negócios, bem como garantir que eles cumpram esses padrões.
- Análise do cliente: ele pode ser usado para analisar o comportamento do cliente e melhorar a experiência do usuário, identificando padrões de uso, preferências e problemas que afetam a satisfação do cliente.
- Análise de vendas: ele pode ser usado para analisar o desempenho de vendas, identificar padrões de compra de clientes e melhorar a lucratividade dos negócios.
- Análise de riscos: Com o Process Mining, os riscos do negócio como fraudes, erros ou problemas de segurança, são identificados e avaliados para tomar medidas e minimizá-los.
Quais ferramentas posso usar?
Existem diversas ferramentas para Process Mining. Alguns dos mais populares são:
- ProM: É uma plataforma de software que permite a análise de processos.
- Disco: Se você é um estudante, pode obter a licença gratuita para usá-lo. O Disco é fácil de usar e inclui visualização de processos e identificação de problemas.
- Celonis: Ele se concentra na melhoria dos processos de negócios em tempo real. O Celonis inclui a identificação de problemas nos processos, a análise de eficiência e a automatização de processos.
- PM4PY: É uma biblioteca Python. Ele fornece ferramentas e algoritmos para descobrir, analisar e melhorar os processos de negócios.
Quais dados eu preciso para fazer Process Mining?
Os dados necessários para fazer a mineração de processos podem ser resumidos em quatro elementos principais: IDs, atividades, timestamps e durações. Esses elementos são os que permitem analisar os processos de negócios e obter informações úteis para melhorá-los.
- IDs: eles são identificadores exclusivos atribuídos a cada caso ou instância de processo. Por exemplo, se analisarmos o processo de atendimento de uma empresa, cada caso pode ser o registro de uma solicitação de serviço.
- Actividades: As atividades são as ações realizadas no processo. Por exemplo, no processo de atendimento ao cliente, as atividades podem ser registro de solicitação, atribuição de caso e resolução de problemas.
- Timestamps: São os momentos em que as atividades são realizadas. Isso permite ver a ordem em que as atividades são executadas e analisar o tempo que cada uma leva. Por exemplo, se um cliente solicitar atendimento às 10h00. m. e seu problema está resolvido às 10h30. m., você pode analisar o tempo que levou para resolver o problema.
- Durações: As durações são o tempo necessário para concluir cada atividade. Isso permite analisar a eficiência do processo e detectar possíveis problemas (bottlenecks). Por exemplo, se uma atividade leva muito mais tempo que as demais, você pode analisar por que isso está acontecendo e tomar providências para melhorá-la.
Process Mining com PM4PY
PM4Py é uma biblioteca Python para executar tarefas de Process Mining e pode ser usada para analisar arquivos no formato XES, como BPI Challenge 2017.xes.gz. Este dataset foi usado na competição BPI Challenge 2017 e contém dados de eventos reais de pedidos de empréstimos de um instituto financeiro holandês.
O objetivo da competição era descobrir padrões de comportamento nos dados e usá-los para otimizar o processo de empréstimo. O objetivo deste tutorial é ensinar como usar o PM4PY para visualizar o processo e encontrar possíveis padrões.
Exportamos os dados .xes para Python da seguinte forma:
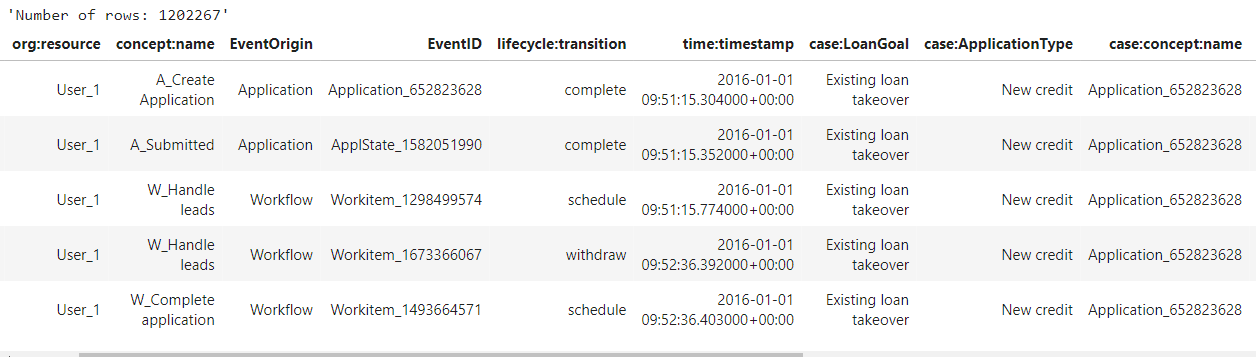
Agora, aplicando a teoria dos dados necessários para fazer Process Mining a este dataset, obtemos o seguinte:
- IDs: case:concept:name.
- Actividades: concept:name.
- Timestamp: time:timestamp.
Para este tutorial, uma nova coluna chamada new_concept onde extraímos a primeira letra das atividades para simplificar o processo de empréstimo. Por exemplo, na coluna concept:name as actividades são A_Create Application, A_Submitted, etc. Na coluna new_concept eles ficam assim:
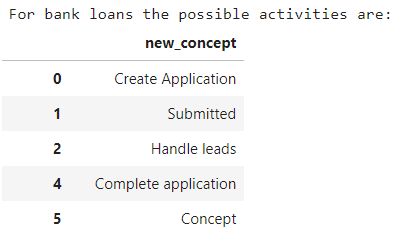
As atividades possíveis neste processo são 24 no total. Agora vamos ver os identificadores que temos para cada aplicação e quantos registros existem no dataset:
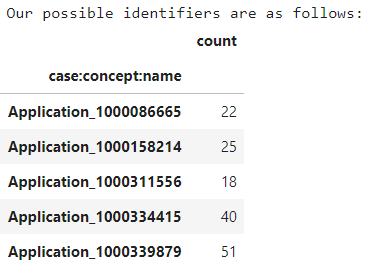
Agora que temos os dados necessários para visualizar nosso processo, utilizamos a biblioteca PM4PY para nos dar uma ideia do que acontece em nosso processo.
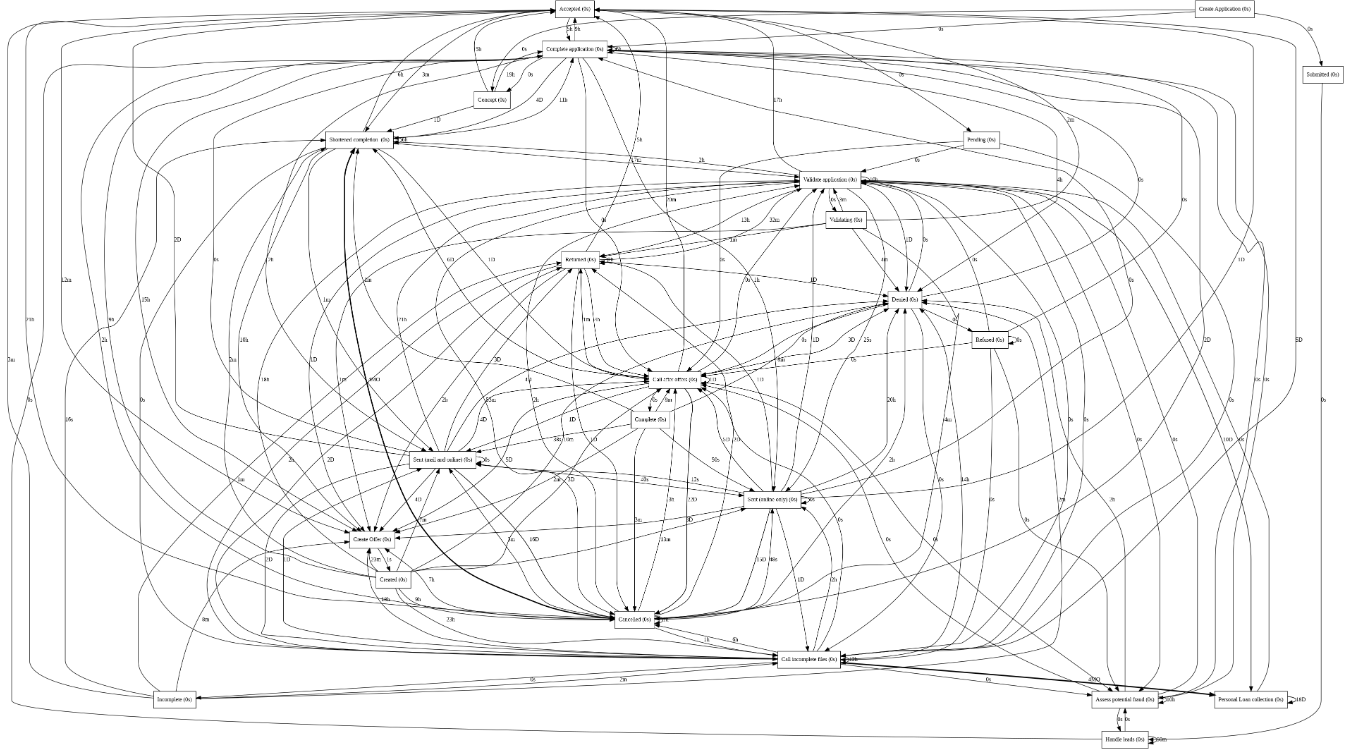
Como você pode ver na imagem, é muito difícil ler o diagrama. Chamamos isso de Modelo Espaguete (Spaghetti Model) já que os diferentes caminhos se entrelaçam de forma complexa e, como o nome diz, parece um prato de espaguete. Isso significa que o processo é difícil de entender e seguir, pois são muitas opções e caminhos diferentes que se juntam de forma confusa.
Em geral, isso ocorre quando o processo evoluiu ao longo do tempo ou foi modificado por diferentes pessoas e departamentos sem o devido planejamento. Mas você provavelmente está se perguntando como podemos resolver isso?
Existem diferentes soluções que a empresa pode adotar para resolver esse processo, seja identificando áreas problemáticas, redesenhando o processo com a ajuda de especialistas da área ou documentando o processo. Partindo do princípio que não temos a ajuda de um especialista na área, vou mostrar como exemplificar o modelo por meio de estatísticas para ajudar a redesenhar o processo.
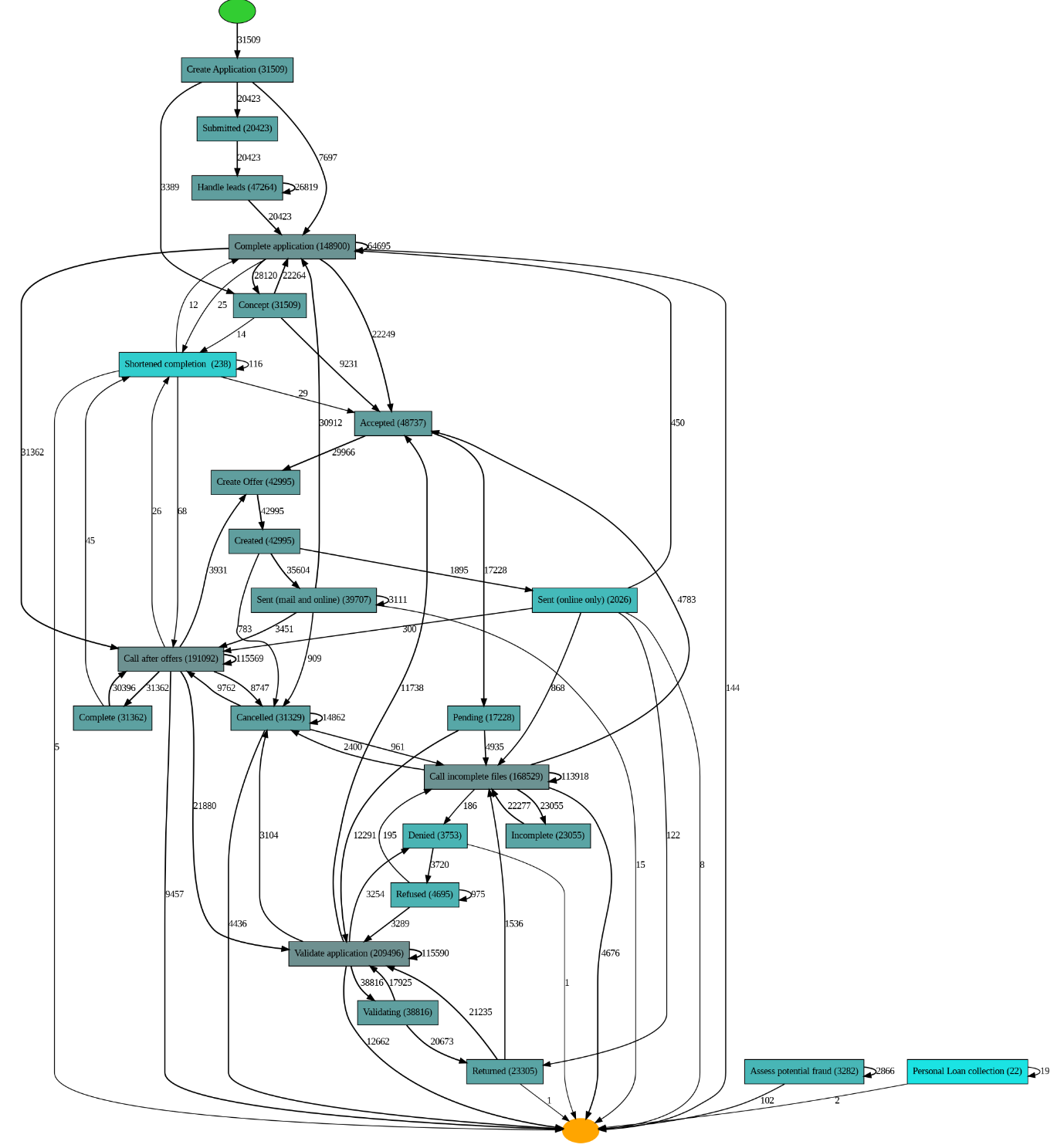
Como pode ser visto, o processo pode ser melhor compreendido, pois estamos ajustando parâmetros para entender quais atividades são relevantes e quais não são. Como você pode ver, no código que usamos discover_heuristics_net com três parâmetros ajustáveis: dependency threshold, threshold e loop two threshold. Eu explico em termos fáceis o que eles significam:
- Dependency threshold: é o limite estabelecido para determinar se uma atividade depende de outra atividade. Se o valor de dependency threshold é alto, significa que é necessário um grande número de atividades em comum para que duas atividades sejam consideradas dependentes.
- Threshold: É o limite estabelecido para determinar a frequência mínima com que uma atividade deve ocorrer para ser considerada relevante. Se o valor de threshold é alto, significa que uma atividade deve ocorrer com muita frequência para ser considerada importante.
- Loop two threshold: é o limite estabelecido para determinar quantas vezes uma atividade pode ocorrer dentro de um loop antes de ser considerada um "loop de dois" (duas atividades que se repetem). Se o valor de loop two threshold é alto, significa que é necessário um número maior de repetições para que duas atividades sejam consideradas duas voltas.

Conclusión
Agora que você já sabe o que é Process Mining e para que serve, espero que essas ferramentas ajudem você a otimizar, detectar problemas e monitorar seus processos. Lembre-se que existem parâmetros neste código que podem ser ajustados para obter diferentes perspectivas sobre o processo e encontrar padrões nos dados.
Eu deixo o código em mim GitHub e convido você a tentar executá-lo alterando parâmetros ou com dados de sua empresa.
Até logo!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.