Reconhecimento e geração de voz com Whisper, gTTS e Python


A Inteligência Artificial (IA) continua a se expandir em todas as áreas de nossas vidas. Principalmente neste 2023, onde os modelos generativos se tornaram relevantes. Não apenas chats inteligentes como ChatGPT, ou geradores de código como GitHub Copilot, ou modelos que permitem a geração de imagens realistas como DALL·E 3, se tornaram populares, também há novos desenvolvimentos no campo de reconhecimento e geração de voz.
Neste tutorial revisaremos dois tipos de ferramentas para trabalhar com áudio em Python:
- Whisper, uma biblioteca que realiza o reconhecimento automático de fala, dado o áudio, transcreve-o em texto, foi criada pela OpenAI. Suporta a capacidade de reconhecer vozes em uma ampla variedade de idiomas.
- Y gTTS (Google Text-to-Speech), uma biblioteca que transforma texto em áudio, utilizando a interface do Google Translate.
Começaremos explicando como ambos são instalados, depois vários exemplos em Python + Whisper + gTTS serão expostos e explicados.

Instalação
Ambas as bibliotecas podem ser instaladas com pip, o gerenciador de pacotes Python.
pip install gTTS
pip install git+https://github.com/openai/whisper.git
Caso a instalação falhe, é provável que esteja faltando algum pré-requisito. Para isso, recomendamos visitar os repositórios de cada biblioteca onde são explicadas as soluções para estes tipos de problemas:
Para verificar se eles foram instalados corretamente, você pode verificar isso – no Linux – com o comando which, que retorna o caminho onde o executável está localizado.
which gtts-cli
which whisper
Um exemplo preliminar (terminal)
Neste exemplo começaremos usando ambas as bibliotecas no terminal. Na próxima seção veremos como usá-los com Python.
Então, primeiro vamos criar um áudio a partir de um texto usando gTTs:
gtts-cli "¡Hola, Listopro!" --lang es --output saludos.mp3Agora com o áudio gerado, saludos.mp3, nós transcrevemos com Whisper:
>> whisper saludos.mp3 --language Spanish
[00:00.000 --> 00:01.560] Hola. Listo Pro.Com isso temos agora o ciclo completo: texto para áudio e áudio para texto.
Observe que o Whister também permite aplicar uma tradução direta para o inglês:
>> whisper saludos.mp3 --language Spanish --task translate
[00:00.000 --> 00:02.000] Hello. ListoPro.
(Na versão atual do Whisper, a tradução só é possível para o inglês).
Recomendo que você revise as demais possibilidades oferecidas por cada biblioteca com a bandeira --help :
gtts-cli --help
whisper --help
Usando o Whisper + Python
Depois de ter certeza de que o Whisper está instalado em seu computador, procedemos a um teste, para isso criamos um arquivo chamado test_whisper.py com o seguinte código:
import whisper
model = whisper.load_model("base")
audio = whisper.load_audio("saludos.mp3")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)
Agora passamos a explicar cada linha:
import whisper
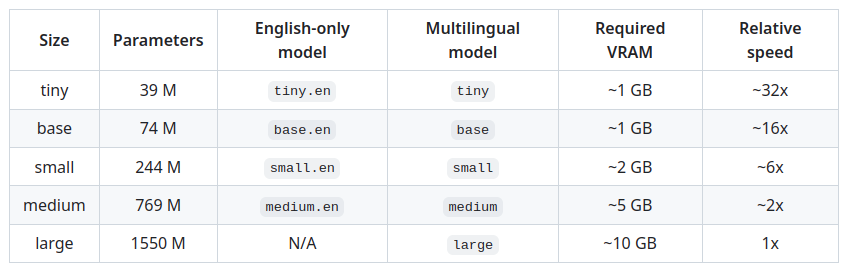
model = whisper.load_model("base")Aqui é carregada a biblioteca Whispter e em seguida é carregado o modelo pré-treinado que será utilizado para poder transcrever. Existem múltiplas opções, neste exemplo usaremos "base", mas poderiam ser usados modelos menores ou maiores, que retornariam os resultados mais rápido ou mais lento. A partir desta escolha a qualidade do resultado pode ser afetada. Em qualquer caso, depende do áudio em questão. Sugerimos que você revise a tabela abaixo:
audio = whisper.load_audio("saludos.mp3")
audio = whisper.pad_or_trim(audio)
En la primera línea se carga el audio saludos.mp3 e, na seguinte, a função pad_or_trim preenche e corta o áudio em espaços de 30 segundos. Isto é para um melhor desempenho do decodificador (veremos isso a seguir).
mel = whisper.log_mel_spectrogram(audio).to(model.device)Um espectrograma log-Mel é uma representação de áudio que combina recursos de espectrogramas e escala log-Mel para capturar informações sonoras relevantes. Ou seja, permite detectar os padrões de áudio produzidos pela voz: entonação, ritmo, velocidade, todas informações necessárias para nutrir o modelo e conseguir uma melhor transcrição.
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
Aqui, graças ao espectrograma log-Mel e ao modelo Whisper, descobrimos qual idioma está sendo falado no áudio. Da seguinte forma: o modelo atribui uma probabilidade a cada idioma e exibe na tela aquele que obtiver maior, neste caso foi “es” (espanhol).
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)
A função DecodingOptions é necessária caso você queira adicionar atributos específicos para transcrição (decodificação). Neste caso, como não temos nada de especial, simplesmente criamos um objeto padrão e o atribuímos à variável options. A seguir vem o importante: a transcrição é feita com a função decode, dando como argumento o modelo Whisper, a variável mel (do espectrograma) e as opções de decodificação. Por fim, podemos exibir na tela a proposta de transcrição do modelo para o arquivo saludos.mp3:
Detected language: es
Hola. Listo, pro.
Usando o gTTS + Python
Usar gTTS com Python é muito simples, pois sua API é minimalista. Vejamos um exemplo:
from gtts import gTTS
tts = gTTS('Hola, ¿qué tal te ha parecido este tutorial para Listopro?', lang='es')
tts.save('saludos.mp3')
A primeira coisa é carregar o módulo gttsda biblioteca gTTS. Então o objeto tts é criado para geração de áudio, o primeiro argumento é o texto e o segundo é o idioma do texto. Neste caso é espanhol. Finalmente, o objeto é salvo tts, dando um nome ao arquivo de áudio, neste caso saludos.mp3.
Integração: Whisper + gTTS + Python
A integração torna-se óbvia. Primeiro criamos áudio em espanhol com gTTS e depois o transcrevemos com Whisper. Vamos ver isso!
Primeiro criamos o áudio em um arquivo chamado integracion.py:
from gtts import gTTS
tts = gTTS('Hola, este es un ejemplo que necesito transcribir para Whisper', lang='es')
tts.save('integracion.mp3')Agora, do arquivo o mesmo arquivo integracion.py prosseguimos adicionando a parte do Whisper relativa à transcrição:
import whisper
model = whisper.load_model("base")
audio = whisper.load_audio("integracion.mp3")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detectando el idioma: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)E só temos que executar:
> python3 test_whisper.py
Detectando el idioma: es
Hola, este es un ejemplo que necesito transcribir para Guisper.Como podemos perceber: ele errou no nome “Whisper” gerando “Güisper”, o que é correto já que o “Wh” não faz parte do espanhol, portanto, ele muda para “Gü”. Muito perspicaz!

Conclusão
Os modelos generativos são muito úteis para tarefas como transcrição e geração de fala. Embora a qualidade máxima do modelo seja alcançada com vozes em inglês (já que foi treinado com mais dados nesse idioma), os resultados em espanhol são aceitáveis. Bastante aceitável. E espera-se que continuem a aumentar em qualidade ao longo do tempo. Agora são melhores do que várias ferramentas de não muitos anos atrás que, por um lado, transcreviam mal e, por outro, geravam uma voz robótica claramente falsa.
Por experiência pessoal posso dizer que ao testar o Whisper com áudio de 30 minutos (em inglês), os resultados foram muito bons (embora, claro, possa levar vários minutos dependendo do computador em que você o executa). O resultado pode ser visto neste entrevista, feita para um cientista da computação.
Será normal que estas ferramentas continuem a evoluir e a integrar-se com outras, como a tradução automática de voz de um idioma para outro, ou modelos que fazem alterações num vídeo (por exemplo, movimento dos lábios). Este último é algo que começa a despertar muito interesse na comunidade. Chegará o dia em que não saber outro idioma não será mais um problema graças aos modelos de voz generativos?
Continue aprendendo
Whisper
Para continuar aprendendo o Whisper, recomendo os seguintes recursos:
- Um tutorial Whisper + Python muito bom para transcrever um vídeo do YouTube: https://towardsdatascience.com/speech-to-text-with-openais-whisper-53d5cea9005e
- Um vídeo de introdução ao Whisper, “Tutorial - como usar o Whisper do zero” por Beatriz Molina. Link: https://youtu.be/89h9LIgI0gQ?si=hth4PUhT7IJdNojD
- Para uma introdução teórica ao Whisper, recomendo verificar seu artigo: https://cdn.openai.com/papers/whisper.pdf
gTTS
No caso do gTTS recomendo a leitura dos tutoriais abaixo:
- Um bom exemplo de uso de gTTS com Python adicionando uma interface gráfica: https://python.plainenglish.io/text-to-speech-conversion-using-python-with-gtts-eb4aa0f6dfb7
- Outro bom tutorial, e na mesma linha do anterior, é o seguinte: https://levelup.gitconnected.com/make-your-python-program-speak-310766534fbf
Referências
- A documentação do gTTS: https://gtts.readthedocs.io/en/latest/
- Exemplos do Whisper em Python: https://colab.research.google.com/github/openai/whisper/blob/master/notebooks/LibriSpeech.ipynb
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.