Seu primeiro modelo de Inteligência Artificial: área da saúde


Graças à revolução do hardware, já existe a capacidade computacional para realizar operações algébricas complexas, base da inteligência artificial. Agora podemos programar desde algoritmos simples, como regressão linear ou Fuzzy Logic (usado na programação de máquinas de lavar), até processamento de linguagem natural, como Siri da Apple ou Alexa da Amazon. Além disso, e como parte de uma política de democratização do aprendizado, não é mais necessário ter uma supermáquina para programar com GPU ou TPU, mas podemos usar recursos online gratuitos como Google Colab ou DeepNote para mergulhar no mundo emocionante de Inteligência Artificial.
Inteligência Artificial na área da Saúde
O uso de aprendizado de máquina se espalhou para diferentes áreas, como a indústria automotiva (com carros inteligentes) ou streaming, com algoritmos que aprendem constantemente com nossos gostos, para que suas recomendações sejam personalizadas e precisas. Na área da Saúde, o projeto mais conhecido é provavelmente o do IBM Watson Health, hoje conhecido como Merative, que tem feito avanços importantes no diagnóstico de doenças e seus tratamentos.
O desenvolvimento de software para previsão de doenças não é algo novo. Há pesquisas no PSG College of Arts and Science para prever doenças cardíacas com os algoritmos Naive Bayes e Support Vector Machine, com uma precisão superior a 70% [1]. Naive Bayes é um algoritmo de classificação de Machine Learning baseado no teorema estatístico de Bayes. Support Vector Machine é um algoritmo de aprendizado supervisionado usado para regressão e classificação.
Outro dos desafios atuais para os pesquisadores é o diagnóstico precoce da retinopatia diabética, complicação do diabetes que afeta a visão. O conjunto de dados consiste em imagens do interior do olho, tiradas por uma câmera especial. O processamento engloba detecção, segmentação de gravidade e localização em marcos para detecção de retinopatia, por meio de métodos estatísticos, métodos de classificação, redes neurais artificiais, Deep Learning, entre outros [2].
Neste artigo, trabalharemos em um conjunto de dados público hospedado no Kaggle, composto por 27 perguntas sobre saúde mental na indústria de tecnologia. Da mesma forma, realizaremos um modelo de classificação com K-means, um algoritmo de aprendizado não supervisionado cujo objetivo é agrupar dados com base em suas características.
Para o ambiente de trabalho
Para este tutorial usaremos o ambiente de trabalho fornecido pelo Google Colab.
Importamos a unidade e conectamos ao ambiente de execução, que solicitará permissões de acesso.

Por outro lado, para o projeto, usaremos o conjunto de dados Kaggle Mental Health in Tech Survey. Para baixá-lo, é necessário criar uma conta na plataforma e, em seguida, acessar a conta. Navegamos até a opção API, onde clicaremos em Create New API Token e será baixado automaticamente um arquivo chamado kaggle.json, que salvaremos em uma pasta dentro do nosso Drive.


Em seguida, usamos a biblioteca os para navegar entre nossos arquivos e, em seguida, salvamos o arquivo kaggle.json na pasta de nossa escolha em nossa unidade Drive.

Uma vez lá dentro, navegamos com o comando %cd até o caminho onde está armazenado nosso arquivo kaggle.

Com o exposto acima, agora é possível baixar o conjunto de dados do Mental Health in Tech Survey. Acesse o link e procure os 3 pontinhos à direita para copiar o comando da API.

Depois de copiado, cole-o na próxima célula do seu notebook no Colab. Não se esqueça de colocar um “!” à frente para baixar o arquivo para o seu diretório.

Perfeito! Agora é necessário descompactar o arquivo baixado mental-health-in-tech-survey.zip, com o método !unzip. Se achar pertinente, você pode criar uma pasta específica para salvar os dados descompactados.

Pré-processamento de dados
Com o arquivo descompactado e os dados em formato csv, podemos explorá-los e manipulá-los com a ajuda da biblioteca Pandas. Portanto, importamos a biblioteca para o nosso notebook.

Salvamos o arquivo como dataframe na variável df e lemos o arquivo csv com o método pandas read_csv. Em seguida, copiamos dentro dos parênteses o diretório e o arquivo csv entre aspas simples ''. O método df.head(5) nos permite exibir as cinco primeiras colunas do conjunto de dados:


O método df.tail() nos permite exibir as últimas cinco colunas.

O método df.columns retorna as 27 colunas do nosso conjunto de dados.

Usamos o método df.describe pois nos permite ter uma descrição estatística do conjunto de dados. Neste caso, considere apenas as métricas da coluna Age, pois é a única coluna com dados contínuos. As outras 26 colunas são dados discretos, neste caso categóricos.

Para realizar uma análise por coluna, utilizamos o método value.counts com a variável 'supervisor' e observamos seu comportamento, obtendo 516 dados para sim, 393 para não e 350 para alguns deles. Desta forma, podemos analisar todas as variáveis discretas.

Para finalizar o pré-processamento dos dados, eliminamos com o método Pandas drop as colunas que não utilizaremos na análise. Neste caso, seriam Timestamp, porque nesta análise a data é irrelevante, Country e State porque não vamos polarizar por região geográfica. Também removeremos Obs_consequence porque, de acordo com o conjunto de dados, esta pergunta neste campo está relacionada ao respondente ter ouvido ou observado comportamento negativo relacionado à saúde mental de um colega de trabalho em seu espaço. Como não vamos abordar essa análise neste tutorial, eliminamos da mesma forma a coluna Comments, campo onde os respondentes podem elaborar, o que geraria ruído em nossa análise por não ser uma variável discreta ou contínua.
Ao remover essas variáveis, executamos um trabalho superficial de limpeza de dados que é realizado por um cientista de dados. Este processo consiste em corrigir ou deletar dados que estejam incorretos ou que não estejam no formato estabelecido. Não há uma maneira definida de como executar essa limpeza, pois os processos variam de processo para processo. Neste artigo, removemos as colunas Timestamp, Country, State, Obs_consequece e Comments porque não contribuíram para o prognóstico da análise de dados.
Os parâmetros do eixo e do local devem ser definidos ou o método assumirá os valores padrão e nenhuma das colunas selecionadas será removida. Para mais informações, consulte a documentação oficial do Pandas.

Implementação do algoritmo K-means
Para este tutorial vamos contar com o Pycaret, uma biblioteca de código aberto que permite que algoritmos de Machine Learning trabalhem com pouco código, além de ser intuitivo e uma ótima ferramenta para escolha de modelos. Outras opções para trabalhar com algoritmos de Machine Learning seriam o Tensorflow e o Pytorch, ambos muito populares e com uma excelente comunidade, principalmente no StackOverflow.
Ao final das etapas deste artigo, seremos capazes de:
- Trabalhar com dados reais importados da maior e mais profissional comunidade online de Data Science e Machine Learning do mundo.
- Configurar um ambiente de trabalho Opensource, desde a preparação dos dados, até a instalação da biblioteca e configuração do módulo de cluster não supervisionado do PyCaret.
- Criar um modelo não supervisionado e treine-o.
- Salvar os pesos do modelo para implantação futura.
Instalamos a biblioteca no notebook com pip.

Você pode obter erros ao instalar o Pycaret em relação à compatibilidade do Numpy com o Pycaret. É por isso que é recomendável trabalhar com uma versão Numpy de 1.21 ou inferior.

Em seguida, importamos pycaret.clustering para nosso notebook. Modelos de regressão também podem ser trabalhados, mas neste caso trabalharemos apenas com clustering.

Preparamos os dados para o modelo, salvando o dataframe na variável data. Os valores de frac=0.9 e random_state =1, nos permitem dividir o dataset em 90% para treinamento e 10% para previsões.
Essa é uma prática comum ao desenvolver modelos preditivos, usando divisões 80/20 ou 70/30. O conjunto de dados também pode ser dividido em três partes, uma porcentagem para treinamento, outra para validação e, finalmente, uma porcentagem final para teste. Não existe uma regra oficial de como o conjunto de dados deve ser distribuído, mas uma grande porcentagem é recomendada para treinamento. O valor de random_state permite implementar um valor de semente para a distribuição do conjunto de dados.

Usamos o método de configuração Pycaret para inicializar o processo. Na saída da célula observamos que ela leva apenas uma coluna como numeric (neste caso age), as demais são tomadas como categorias. Se a qualquer momento você quiser trabalhar com essas categorias de forma numérica ou booleana, pode especificar neste campo.


O próximo passo é criar o modelo chamado K-means. Se o número de clusters não for definido, ele se tornará quatro por padrão. Como vemos na saída da célula, os clusters são o número de centróides nos quais os dados serão agrupados.

Para definir manualmente o número de clusters ou agrupamentos que queremos para nosso modelo, definimos dentro do método create_model, com a variável num_clusters.

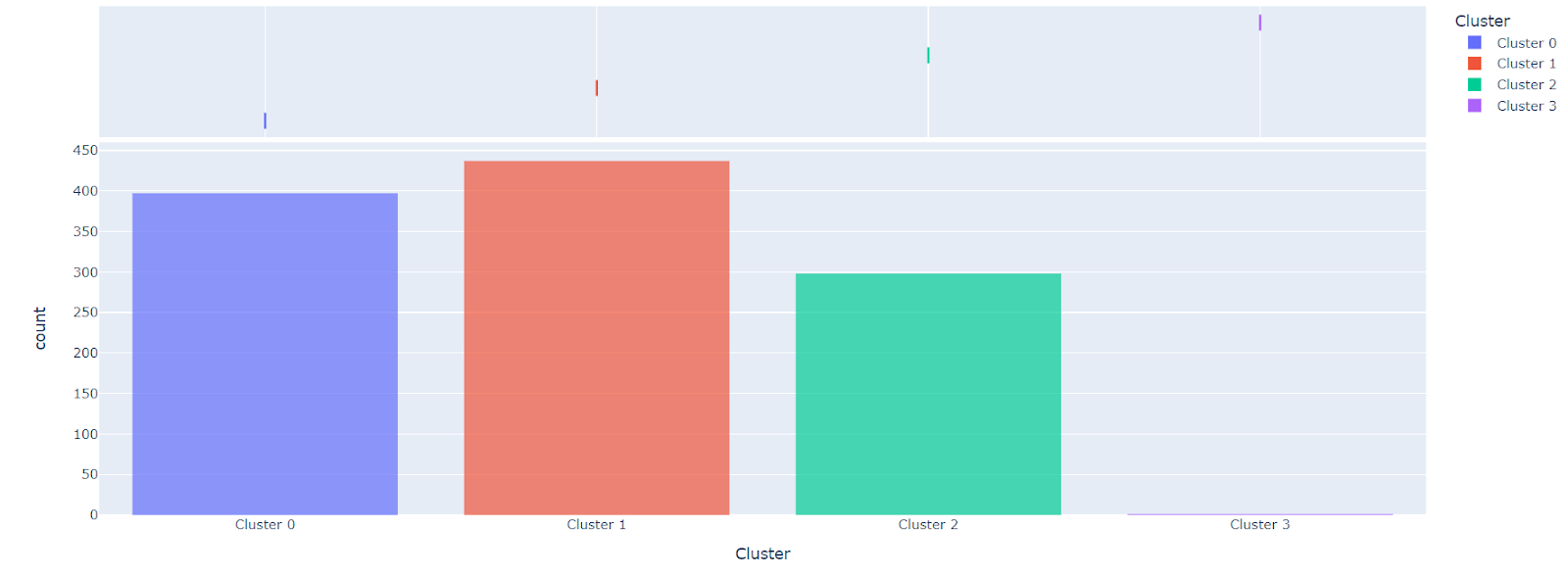
Por fim, atribuímos o modelo K-means previamente definido, sem especificar o número de clusters, pelo que teremos 4 categorias. Observando os resultados em kmean_results.head(), notamos que apareceu uma nova coluna chamada Cluster, contendo 4 rótulos possíveis: cluster 0, cluster 1, cluster 2 e cluster 3.


Podemos visualizar as categorias do nosso modelo com o método plot_model. Quando representados graficamente, existem 3 grandes grupos e um que contém apenas uma amostra. A partir destes centróides podemos realizar várias análises consoante as questões que temos, relativamente aos nossos clusters.

Finalmente, salvamos o modelo com o método save_model no diretório atual em que estamos trabalhando. Neste caso será denominado Final Kmeans Model 20Nov2022.

Parabéns! Agora você sabe como implementar um algoritmo de agrupamento de Machine Learning com as ferramentas PyCaret e Google Colab, bem como usar um conjunto de dados estruturado Kaggle. As próximas etapas como desenvolvedor de IA, cientista de dados ou analista de dados são realizar uma visualização de dados. Para isso, você pode usar as ferramentas do Matplotlib, Seaborn ou Tableau, todas entre as mais populares.
Como pudemos ver, as ferramentas já consagradas em Machine Learning como Pycaret, Tensorflow, Sklearn ou Pytorch permitem a implementação de modelos de aprendizado supervisionado e não supervisionado de forma mais fácil e intuitiva, o que significa que a curva de aprendizado não é um impedimento. sua implementação. Além disso, trabalhamos com aprendizado do tipo caixa preta, no qual não é necessário (mas é recomendado) saber o que acontece dentro do modelo. Basta conhecer os parâmetros de entrada e a saída que procuramos.
A saúde mental deve ser uma prioridade não só das pessoas, mas das instituições que nos empregam. Nenhum algoritmo ou chatbot pode substituir o trabalho de um profissional médico, embora os algoritmos possam nos ajudar a detectar quem precisa de ajuda e apoiar um diagnóstico médico. O conjunto de dados é uma amostra completa e representativa que pode ser explorada de várias maneiras. Khurana et al [3] exploram outros métodos além de kmeans com o mesmo conjunto de dados, então convido você a ler o trabalho deles.
Fontes consultadas
[1] Vembandasamy, K., Sasipriya, R., & Deepa, E. (2015). Heart diseases detection using Naive Bayes algorithm. International Journal of Innovative Science, Engineering & Technology, 2(9), 441-444.
[2] Soomro, T. A., Gao, J., Khan, T., Hani, A. F. M., Khan, M. A., & Paul, M. (2017). Computerised approaches for the detection of diabetic retinopathy using retinal fundus images: a survey. Pattern Analysis and Applications, 20(4), 927-961.
[3] Khurana, Y., Jindal, S., Gunwant, H., & Gupta, D. (2022). Mental Health Prognosis Using Machine Learning. Available at SSRN 4060009.
Documentação do Pandas: https://pandas.pydata.org/docs/
Documentação do Pycaret: https://pycaret.gitbook.io/docs/
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.