Simplificando o webscraping com Selenium e Python


Quando queremos obter grandes quantidades de informações ou fazer testes em aplicações web, fica inviável fazer essa tarefa manualmente dependendo da sua necessidade.
Uma ferramenta comumente utilizada para automatizar essa tarefa é o selenium, um projeto de código aberto com várias funcionalidades que permitem a automação de navegadores com diferentes linguagens de programação. Neste artigo, vamos ver o passo a passo de como instalar e configurar o selenium para criar simples algoritmos de webscraping com o Python.
Primeiramente, vamos iniciar um ambiente virtual para instalar as bibliotecas necessárias:

Depois de criado, agora vamos ativar o ambiente virtual:

Com o ambiente configurado, as bibliotecas que instalaremos serão: o Selenium para fazer o webscraping, o Decouple para configurar variáveis de ambiente e o Webdriver Manager para se encarregar de baixar o driver adequado para o navegador. Através do seguinte comando no terminal:

Agora vamos criar um arquivo chamado main.py e importar os módulos das bibliotecas necessários para o projeto:
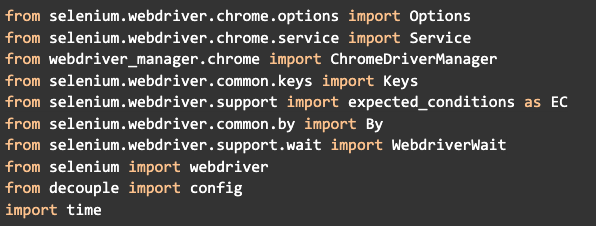
É importante saber que cada um destes módulos vão ter uma utilidade específica. O processo de extrair dados de um site nem sempre é algo simples, uma vez que existem sites que são estáticos e outros que são dinâmicos (mudam conforme a interação). Alguns mudam apenas devido ao seu funcionamento normal, enquanto outros têm sistemas específicos programados para evitar que sejam controlados por robôs.
Sistemas anti-bots: o que são?
Para que o seu robô acesse um determinado site, é preciso fazer uma requisição como qualquer outro usuário e então receber a resposta do servidor. A diferença entre eles basicamente é que enquanto o usuário tem uma certa limitação para interagir com o site, o robô pode ficar acessando várias vezes o site para puxar dados. Levando em consideração que para cada requisição é necessário que o servidor performe um certo processamento para então devolver uma resposta, isso pode escalar muito rápido, deixando o site mais lento para os outros usuários que estão tentando acessar caso não haja uma infraestrutura preparada para isso (isto poderia ser comparado a um ataque DDOS).
Outras razões por trás do desenvolvimento de sistemas anti-bots, seria, por exemplo, para o site de um jogo online onde através de um robô coletando dados, poderia ser elaborada uma espécie de trapaça. Outro exemplo são os serviços de email, onde seria possível criar diversos endereços para cadastrar em vários serviços (Por isso que existe o famoso Captcha, aquele sistema onde você precisa escrever uma sequência de letras, números borrados ou ainda selecionar imagens semelhantes para provar que você não é um robô).
Existem diversas técnicas tanto para criar quanto para burlar os sistemas anti-bots. Uma forma clássica é quando o sistema detecta que é um robô acessando e começa a banir o IP, o que pode ser contornado utilizando proxies públicas de forma aleatória.
Webscraping no contexto da segurança da informação
Vale ressaltar que essa brincadeira de gato e rato já existe a muito tempo. Pensando no lado do desenvolvedor que está construindo o robô, essa é uma forma de obter grandes quantidades de dados e usufruir de serviços que não estão acessíveis a maior parte dos usuários, o ato de fazer webscraping em si não é um crime, pois tecnicamente estamos apenas acessando informações que estão publicamente disponíveis, porém o que você faz com elas é que pode configurar um crime ou não, como o exemplo dos hacks em jogos, fazer algum tipo de chantagem com os dados ou usá-los para invadir algum sistema.
Agora pensando no lado do desenvolvedor que está projetando sistemas de defesa, a ideia não é criar um sistema infalível, até porque mesmo os mais avançados hoje em dia como o ReCaptcha podem estar com os dias contados com o avanço nas áreas de machine learning e visão computacional. Mas ter o conhecimento dos ataques mais frequentes e a habilidade de desenvolver programas para evitá-los é o mínimo a ser feito, mas que já pode diminuir consideravelmente a quantidade de pessoas com habilidade e dispostas a atacar o seu sistema, uma vez que, aquele que sairá ganhando será o que tem mais conhecimento.
Esse tema da segurança da informação pode render vários artigos por si só, mas essa breve introdução serve para compreendermos o princípio básico de que não existe “bala de prata”, nem para os atacantes, nem para quem está se defendendo e que quando o assunto é segurança, todo cuidado é pouco. Isso significa que, se você detectar que um determinado site está bloqueando o seu acesso, provavelmente vai ter que desenvolver uma solução própria para burlar este sistema.
Detectando sistemas de segurança
Existem algumas formas que podem ser utilizadas para detectar a maneira como o sistema rastreia as suas ações. Depois de ter configurado seu robô -como veremos mais adiante- se em algum momento ele parar de funcionar, alguns testes podem ser feitos, como, por exemplo:
- Limpar os cookies do navegador,
- Acessar com outro navegador,
- Acessar com outro computador ou pelo celular,
- Acessar utilizando outra rede para saber se estão bloqueando o seu IP,
- Investigar o JavaScript do site para saber se ele está enviando a informação para o servidor de que o navegador está sendo controlado por um robô.
Esclarecida a parte teórica, agora vamos para a prática. Depois de importar os módulos, comece criando um objeto da classe Options (será nele que adicionaremos as configurações para o navegador).
Neste caso, como estou utilizando o navegador Brave, adicionei a opção “binary_location” que é o lugar onde está o executável do navegador. As mesmas configurações servem caso você esteja utilizando o Google Chrome, pois o Brave é baseado nele.

A primeira opção serve para evitar que o selenium fique enviando logs para o seu console e o binary_location foi configurado através da função config do módulo decouple. Isso serve para que possamos escrever o valor de uma variável em outro arquivo chamado .env, então na hora que o programa for inicializado, ele vai procurar por esse arquivo e carregar o valor para a memória do programa. Só fazendo um adendo, esse modo de puxar dados de um arquivo .env é utilizado para variáveis sensíveis como por exemplo para os dados de acesso a um banco de dados e esses arquivos devem ser excluídos quando o código for enviado para o GitHub, devendo ser declarado no .gitignore.
Outra opção que pode ser adicionada é o --headless que é utilizado para iniciar o navegador em modo background:

Agora basta configurar o driver, passando para ele as opções que acabamos de definir e o service que é o driver que vai se conectar com o navegador (o módulo ChromeDriveManager vai instalar o driver automaticamente na primeira execução):

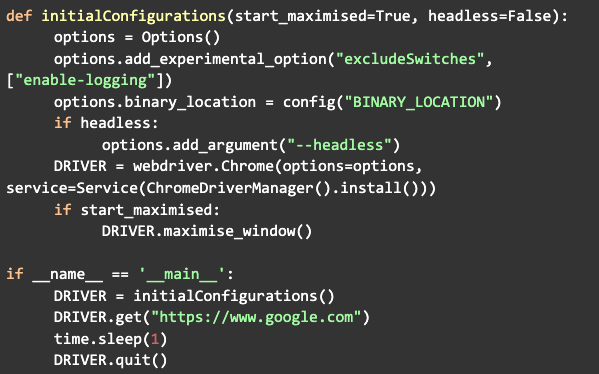
Antes de iniciar o driver, uma configuração que pode ser adicionada é para ele iniciar em modo maximizado:

Agora basta chamar a função get, passando a URL do site que você quer acessar que ao executar o navegador será aberto e fará uma requisição para o site especificado, esperamos alguns segundos com o módulo time, depois fechamos o navegador chamando a função quit:

O próximo passo é começar a buscar pelas informações dentro do site, mas antes, podemos encapsular o código que já criamos em uma função com o nome de configurações iniciais, que será chamada primeiro quando o código for iniciado:
Agora, para procurar pelo item que você deseja, basta abrir o navegador normalmente, colocar o mouse sobre o item, clicar com o botão direito e depois em “inspecionar elemento”.
O navegador vai abrir o código HTML e nele vai conter diferentes tipos de tags HTML com suas propriedades como class, name e ID (geralmente, o melhor é utilizar o ID pois ele é único). Agora vamos fazer uma pesquisa no google só para exemplificar. Primeiro verificamos os parâmetros do input, que vai ser algo parecido com isso:

Aqui podemos ver que o parâmetro name têm o valor “q” e será esse valor que vamos utilizar para acessar esse elemento, então após o get, vamos pegar esse elemento utilizando o módulo By para procurar pelo nome:

Tendo esse elemento definido em uma variável, podemos começar a interagir com ele, enviando um texto, por exemplo:

Quando o texto for enviado, podemos então através do módulo Keys enviar o comando enter, que é representado pelo RETURN:

Então depois que a pesquisa for feita, podemos fazer com que o robô mostre o título de cada link. Para isso, vamos analisar novamente a estrutura do html. Se você abrir as pesquisas do Google, clicar com o botão direito em um título e depois em inspecionar, irá aparecer algo parecido com isso:

Cada um desses grupos de letras e números separados por espaços são as classes desse elemento, alguns sites são mais fáceis de ler o nome das classes e outros não. Para saber qual classe nesse caso é específica para os elementos do mesmo tipo que estamos procurando, podemos testar cada uma.
Então da mesma forma como fizemos com a caixa de texto para pesquisar, faremos para achar os títulos, a diferença é que em vez de utilizar find_element utilizaremos find_elements para achar mais de um elemento ao mesmo tempo, retornando uma lista. Então para cada elemento podemos mostrar no terminal seu texto com um loop:

Outra forma recomendada de procurar por um elemento é utilizando o WebDriverWait que importamos lá no começo, pois muitas vezes a página pode carregar, mas o elemento ainda não está visível. Então, o comando a seguir vai esperar um determinado tempo até as condições esperadas serem válidas:
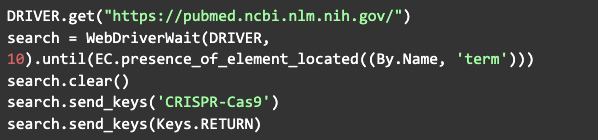
O que este comando está fazendo basicamente é acessar o site do pubmed, achar e selecionar a barra de pesquisa, colocar o termo a ser pesquisado e pressionar enter. Esta instrução serve apenas como exemplo do que pode ser feito, na prática, existe outra forma mais eficiente de fazer pesquisas em determinados sites, através da manipulação da URL. Por exemplo, temos que o comando a seguir teria o mesmo efeito do anterior:

Outra opção de interação é clicar em um elemento:

No exemplo acima, estamos clicando no primeiro artigo que aparece na pesquisa. Neste caso funciona, mas podem haver casos onde clicar com o Python pode gerar um erro, então podemos executar comandos através do JavaScript da seguinte forma:

Além dessas, existem diversas outras funções de cada um dos módulos que importamos e podem ser utilizadas para diferentes propósitos, mas com o conhecimento adquirido neste artigo você já tem uma base e pode começar a criar suas próprias funções e classes para extrair dados e executar ações na maioria dos sites.
Se tiver ficado com alguma dúvida com relação ao código desenvolvido, acesse o repositório do GitHub para mais informações.
Sucesso!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.