Usando scraping com Node.js para categorizar currículos em PDF e separar em pastas

O mundo digital é um vasto repositório de informações em diversos formatos, e os arquivos PDF (Portable Document Format) são amplamente empregados para compartilhar conteúdo de maneira confiável e padronizada. Contudo, manipular e extrair dados específicos de arquivos PDF pode ser um desafio, especialmente quando a meta é automatizar esses processos em um ambiente de desenvolvimento.
Neste sentido, a linguagem de programação node.js surge como uma ferramenta eficaz capaz de superar esses desafios. Este tutorial foi criado para guiar você através da superação desse desafio, usando a poderosa plataforma de programação Node.js em conjunto com a biblioteca "pdf-parse". Com o Node.js, é possível construir um código eficaz para ler arquivos PDF e extrair informações relevantes contidas neles. Além disso, vamos explorar como integrar essa funcionalidade com um banco de dados PostgreSQL, permitindo armazenar e organizar os dados extraídos dos arquivos PDF.
Portanto, leia para explorar, com maior exatidão, a possibilidade da extração de dados de arquivos PDF, utilizando o node.js, enriquecendo suas habilidades de desenvolvimento com mais essa ferramenta valiosa em seu repertório.
Antes de adentrarmos no tema, é indispensável preparar o ambiente adequado. Certifique-se de ter o Node.js instalado em seu sistema, já que ele servirá como base para a construção do código. Caso o Node.js não esteja presente, você pode baixá-lo e instalá-lo com facilidade diretamente do site oficial do Node.js (https://nodejs.org/).
Depois de ter o Node.js instalado, vamos criar um novo diretório para o nosso projeto e instalar as bibliotecas necessárias. O npm, que é o gerenciador de pacotes padrão do Node.js, nos ajudará nessa tarefa. As bibliotecas fs e path são recursos nativos do Node.js e são utilizadas para manipulação de operações de arquivos e caminhos de diretórios, respectivamente, enquanto a biblioteca pdf-parse será nossa escolha para extrair o texto de arquivos PDF.
Este tutorial explora a criação de um programa em Node.js para a organização automatizada de arquivos em pastas com base em palavras-chave. Tal abordagem oferece uma solução prática e eficaz para a organização de documentos, resultando em uma economia considerável de tempo. Ao implementar o código no terminal, o usuário precisa apenas definir a quantidade de categorias desejadas e as palavras-chave correspondentes. Dessa forma, o processo de categorização e organização dos arquivos PDF se torna rápido, eficiente e altamente customizável, atendendo às necessidades individuais de cada projeto.
Agora que compreendemos a importância desse tutorial e o contexto no qual ele se insere, podemos avançar com o passo a passo detalhado da implementação. Vamos explorar cada aspecto do código, desde a interação com o usuário até a categorização dos arquivos PDF e sua organização em pastas.
Prepare-se para adentrar no mundo da automação e eficiência proporcionado pelo Node.js e pela biblioteca pdf-parse!

Com as dependências instaladas, é hora da prática de implementar o código. Criaremos um script em Node.js que irá ler todos os arquivos PDF de um diretório específico, extrair os dados relevantes de cada PDF utilizando a biblioteca pdf-parse.
Dentro do código, usaremos funções assíncronas e promessas para garantir que as operações sejam executadas de forma eficiente e sem bloquear o fluxo do programa.
Passo 1: Configuração Inicial
Inicialmente, verifique se você tem o Node.js instalado em seu sistema. Caso não tenha, você pode baixá-los e instalá-los a partir dos sites oficiais:
- Node.js: https://nodejs.org/
Após ter o Node.js instalado, crie uma pasta chamada “currículos” no mesmo diretório em que será colocado o script.
Dentro da pasta “currículos”, insira os arquivos PDF que contenham as informações de currículos que você irá utilizar.
Em seguida, execute o seguinte comando para criar o arquivo package.json e instalar as dependências necessárias:
Passo 2: Instalação de Depedências
Agora, instalaremos as bibliotecas necessárias. Execute o comando abaixo no terminal:
Explicação das dependências:
- fs: Módulo nativo do Node.js para lidar com operações de arquivo.
- path: Módulo nativo do Node.js para manipular caminhos de arquivos e diretórios.
- readline: Módulo nativo do Node.js que facilita a leitura de entradas do usuário a partir da linha de comando.
- pdf-parse: Biblioteca para extrair o texto de arquivos PDF.
Passo 3: Implementação do Código
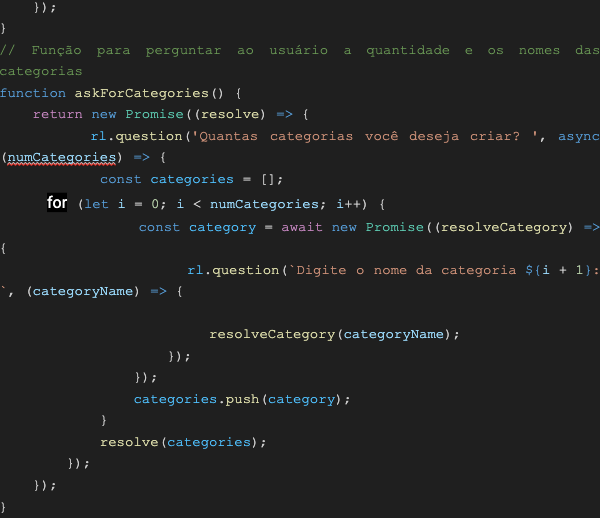
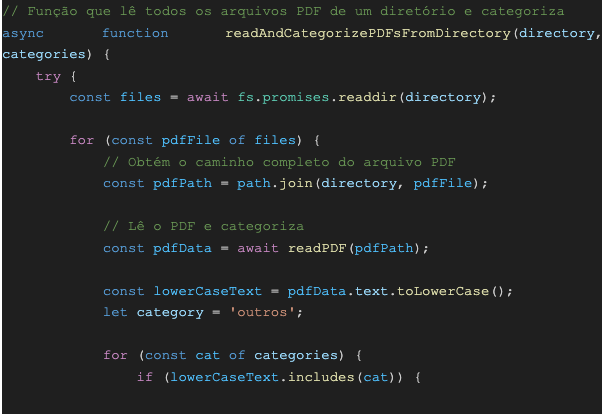
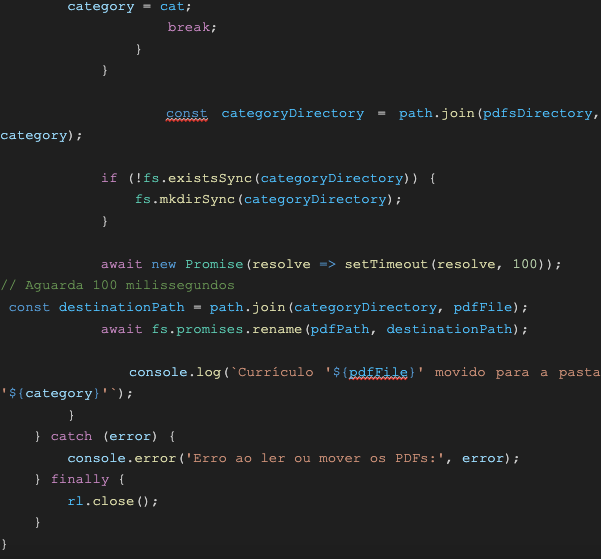
Agora, é o momento de implementar o código. Crie um arquivo chamado ‘node index.js’ e insira o seguinte código:
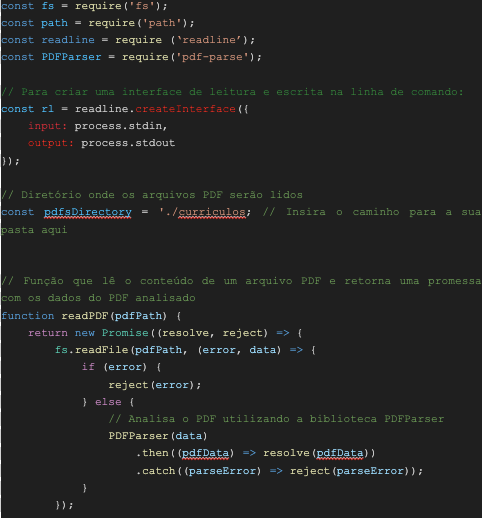
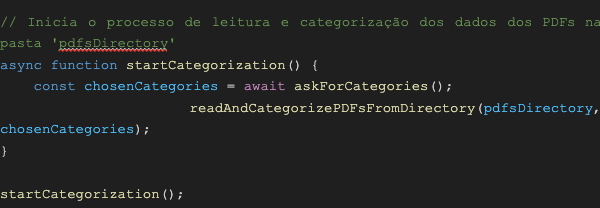
pdfsDirectory: É o caminho do diretório onde os arquivos PDF serão lidos. No código atual, os PDFs devem estar na pasta ./curriculos (na mesma pasta do script).
askForCategories: Essa função visa solicitar ao usuário a quantidade e os nomes das categorias que serão utilizadas para organizar os arquivos PDF.
startCategorization: Função que possui como objetivo iniciar o processo de categorização, ela chama a função anterior (aksforcategories) para obter as categorias determinadas pelo usuário, e em seguida chama a função “readAndCategorizePDFsFromDirectory” para categorizar os arquivos PDF.
readPDF: Função responsável por ler o conteúdo de um arquivo PDF e retornar uma promessa que contém os dados do PDF analisado.
readAndCategorizePDFsFromDirectory: Esta função tem como finalidade ler todos os arquivos PDF do diretório e categorizá-los, com base nas palavras chave encontradas em seus conteúdos.
Passo 4: Executando o Programa
Agora, abra o terminal e digite o seguinte comando:
“node index.js”
Para ilustrar a execução do programa e categorização dos currículos, solicitei ao programa que separasse os arquivos selecionados em quatro categorias: front end, back end, full stack e css, e o que não se enquadra nessas palavras chaves, será separado em uma pasta denominada como outros:

Após a categorização, realizada de forma interativa com o usuário pelo terminal, o programa exibe como ficou a organização dos currículos nas pastas, atendendo aos critérios solicitados pelo usuário:
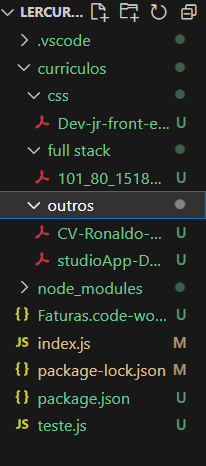
Dessa forma, conforme o programa identificou as palavras-chave solicitadas, após categorizar os arquivos PDF, foi criada uma pasta referente às categorias, e o que não se enquadra nos requisitos solicitados, foi movido para a pasta chamada de “outros”. Utilizando esse código, você pode aprimorar e personalizar os arquivos conforme suas demandas.
Conclusão
Neste tutorial, o objetivo foi mostrar uma solução eficaz para quem procura automatizar processos de organização de arquivos no formato PDF, com a criação de um programa em Node.js para automatizar arquivos em pastas com base em palavras-chave.
No decorrer deste tutorial, exploramos um cenário prático em que a automação de tarefas se mostrou uma solução poderosa e eficiente. Ao utilizar a linguagem de programação Node.js e a biblioteca pdf-parse, fomos capazes de desenvolver um programa capaz de extrair informações relevantes de arquivos PDF e categorizá-los de acordo com palavras-chave específicas. Esse processo não apenas simplificou a organização de documentos, mas também economizou um tempo valioso que poderia ser direcionado para tarefas mais estratégicas.
O tutorial começou com uma introdução abordando a importância dos arquivos PDF no mundo digital e os desafios de manipulá-los. Discutimos a preparação do ambiente de desenvolvimento, incluindo a instalação do Node.js e das bibliotecas necessárias. Em seguida, detalhamos o código passo a passo, explicando cada função e componente envolvido. A introdução da interação com o usuário por meio do readline trouxe uma experiência mais amigável e personalizada à aplicação.
O ponto central do tutorial foi a criação da função que lê e categoriza os arquivos PDF com base nas palavras-chave definidas pelo usuário. A automação desse processo resultou em um ganho significativo de eficiência, reduzindo a necessidade de intervenção manual repetitiva. Essa abordagem pode ser aplicada em diversos cenários, desde a organização de currículos até a classificação de documentos comerciais.
Ao final, discutimos brevemente o conceito de automação, ressaltando sua relevância em otimizar tarefas rotineiras e liberar recursos para atividades mais estratégicas e criativas. Através deste tutorial, você não apenas aprendeu a criar um programa funcional, mas também compreendeu a importância de automatizar tarefas em diversos contextos.
Em suma, a automação é uma ferramenta valiosa no mundo moderno, e este tutorial ofereceu um exemplo prático de como ela pode ser implementada por meio da programação. Esperamos que você tenha adquirido conhecimentos úteis e inspiração para explorar ainda mais as possibilidades da automação em suas atividades diárias e projetos futuros.
O processo de organização de arquivos que é feito de forma manual pode ser extremamente demorado, especialmente quando há uma quantidade exorbitante de documentos para categorizar e organizar por pastas. Assim, ao implementar o código desenvolvido e apresentado neste tutorial, esse processo pode ser simplificado, com um comando no terminal, na qual os usuários precisarão apenas fornecer a quantidade de categorias desejadas e as palavras-chave que serão usadas para categorizar os arquivos.
Essa abordagem traz inúmeros benefícios, como a redução de erros e otimização do fluxo de trabalho, além da melhor gerência do nosso tempo, ao possibilitar que o programa automatize tarefas repetitivas e propensas a erros, dessa forma o usuário pode se concentrar em tarefas mais criativas e estratégicas.
Portanto, se você está buscando otimizar a organização de documentos, este tutorial pode ser a solução prática e acessível. Agora, você possui em mãos um poderoso instrumento para automatizar a categorização de arquivos PDF com base em critérios definidos, visando economizar tempo e tornar a atividade mais eficiente.
A economia de tempo obtida por meio dessa automação é inestimável, pois libera o usuário para utilizar seu tempo em atividades mais produtivas, e a medida que nos aprofundamos na programação e desenvolvemos soluções mais complexas, o conhecimento adquirido aqui servirá como base sólida para futuras empreitadas.
No contexto do desenvolvimento de software, a automatização desempenha um papel vital, melhora a qualidade do código e acelera o ciclo de desenvolvimento. Muitas tarefas podem ser automatizadas e amplamente utilizadas em atividades rotineiras do dia a dia.
Por fim, você pode prosseguir com confiança, sabendo que automação tem um poderoso potencial em produtividade e aplicabilidade em vários contexto, espero que esse tutorial tenha inspirado você a explorar mais a fundo as capacidades do node.js e a criar soluções inteligentes para desafios do mundo real.

Referência Bibliográfica
- Documentação oficial do Node.js: https://nodejs.org/
- Documentação da biblioteca pdf-parse: https://www.npmjs.com/package/pdf-parse
- Documentação da biblioteca fs (Node.js): https://nodejs.org/api/fs.html
- Documentação da biblioteca path (Node.js): https://nodejs.org/api/path.html
- Documentação da biblioteca readline (Node.js): https://nodejs.org/api/readline.html
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.