Visualização de dados com Dash Framework: Processo ETL e uso de Python, Plotty Dash e MongoDB


Neste artigo, desenvolveremos um painel que consome dados armazenados em um banco de dados não relacional MongoDB que foi alimentado por meio de arquivos CSV usando Python.

Para englobar este projeto, sua estrutura foi dividida da seguinte forma:
- Processo ETL o ETL Process.
- Visualização de dados.
O que é um ETL Process?
O processo ETL é um processo inteligente de integração de dados que consiste em três fases: extração (extraction), transformação (transformation) e carga (load).
Fase de extração
Nesta fase, o seguinte processo é realizado:
- Extrair dados do arquivo CSV.
- Analisar os dados e interpretá-los, verificando quais dados são importantes e quais são rejeitados.
- Os dados considerados importantes são passados para o processo de transformação.
- Eliminação de anomalias em relação à média.
Fase de transformação
Nesta fase é realizada a limpeza dos dados e o cálculo de mais campos. As atividades comuns incluem:
- Calculae campos como idade, data de nascimento, margem de lucro subtraindo receitas e despesas, entre outros.
- Limpar as informações, como remover espaços vazios.
- Conversão de valores categóricos e valores numéricos.
- Normalização de dados, para que todos os dados tenham o mesmo padrão.
Fase de carga
É o processo de carregamento dos dados transformados. Essa fase interage diretamente com o banco de dados de destino, aplicando restrições para garantir a qualidade dos dados.
Existem duas maneiras de desenvolver o processo de carregamento:
- Rolling: Informações resumidas são armazenadas, geralmente totais ou quartis.
- Acumulação: Um resumo das transações incluídas em um período selecionado é carregado.
O que é MongoDB?
É o chamado banco de dados No-SQL, portanto, não possui uma estrutura tradicional de banco de dados entidade-relacionamento. O MongoDB utiliza documentos JSON com esquemas dinâmicos, alternando o esquema de acordo com a necessidade dos dados.
O que é um Ploty Dash?
É uma biblioteca de interface desenvolvida em Plotly.js e React que permite construir e implantar aplicações de análise de dados. O Dash abstrai a tecnologia e o protocolo construídos por meio do modelo de controlador de exibição de um ambiente da Web, tornando a programação focada na exibição.
Os aplicativos Dash são renderizados no navegador da Web, podem até ser instalados em uma máquina virtual e compartilhados via URL.
Instalação e configuração do MongoDB
É melhor usar os repositórios oficiais do Ubuntu que incluem uma versão estável do MongoDB.
Para começar, a chave pública da última versão estável do MongoDB deve ser importada, aplicando o seguinte:
wget -qO - https://www.mongodb.org/static/pgp/server-6.0.asc | sudo apt-key add -
Atualizamos o Ubuntu com a chave pública importada.
sudo apt-get update
Prosseguimos com a instalação do MongoDB.
sudo apt-get install -y mongodb-org
Nós levantamos o serviço MongoDB.
sudo systemctl start mongod
Reiniciamos o daemon do Ubuntu.
sudo systemctl daemon-reload
Verificamos o status do MongoDB.
sudo systemctl status mongod
Habilitamos o serviço MongoDB.
sudo systemctl enable mongod
Para começar a usar o MongoDB, executamos o mongosh.
mongosh
Configuração do ambiente virtual
Em uma pasta dentro do diretório Ubuntu, criamos um ambiente Python virtual com a seguinte configuração:
sudo apt-get install -y python3-venv
python3 -m venv venv
source venv/bin/activate
Para saber que está dentro do ambiente virtual, verificamos que (venv) aparece como prefixo da máquina:
(venv) kleber@legion:~/dashboard_open$
Dentro do ambiente virtual, instalamos os pacotes necessários, como:
pip install pymongo==3.12.3
Embora exista uma versão mais atualizada, recomendo usar a 3.12.3, para evitar o seguinte erro:
NotImplementedError: Database objects do not implement truth value testing or bool(). Please compare with None instead: database is not None
Posteriormente, instalamos os seguintes pacotes dentro do ambiente virtual:
pip install dnspython
pip install numpy
pip install pandas
pip install python-dateutil
pip install pytz
pip install six
Recomenda-se criar um arquivo com os pacotes instalados dentro do ambiente virtual para que em uma eventual migração de computadores você tenha o mesmo ambiente. É altamente recomendável ter o mesmo ambiente no ambiente de desenvolvimento e produção.
Configuração IDE
Recomenda-se usar o Visual Studio Code e seguir as instruções deste link para adequá-lo às necessidades do projeto.
Instalação e configuração do Dash
No mesmo ambiente virtual, instale as seguintes bibliotecas para configurar o ambiente Dash.
pip install dash
Ao instalar o Dash, a biblioteca de gráficos Plotly está incluída. Posteriormente, o Pandas é instalado para lidar com o cálculo dos dados.
pip install pandas
ETL Process
Fase de extração: Carregar informação CSV
Na pasta principal, um arquivo Python é criado:
touch ETL_process.py
Prossiga com a importação das bibliotecas.
- Pymongo é uma biblioteca que permite interagir com o banco de dados MongoDB.
- Pandas é uma biblioteca que permite carregar o arquivo csv e interagir com dataframes.
- Json é uma biblioteca que permite transformar dataframes em formato Json.
Fase de transformação
Nesta fase são realizados os processos de classificação e contagem, que são as transformações dos dados.
Classificação de dados por sua variedade
Para classificar as informações, cada coluna, ou seja, cada variável do conjunto de dados deve ser analisada. Após a análise dos dados (através do arquivo csv separado) observa-se que a variável 'variety' é classificada em três classes, portanto é classificada desta forma:
setosa_data=iris_dat[(iris_dat['variety'] == 'Setosa')]
versicolor_data=iris_dat[(iris_dat['variety'] == 'Versicolor')]
virginica_data=iris_dat[(iris_dat['variety'] == 'Virginica')]
Outro item importante são as quantidades de cada classe dentro do conjunto de dados. O comprimento de cada array é calculado.
cant_setosa=len(versicolor_datlen(setosa_data)
cant_versicolor=len(versicolor_data)
cant_virginica=len(virginica_data)
cant_tot_variedad = [cant_setosa, cant_versicolor, cant_virginica]
label_variedad =[Setosa','Versicolor','Virginica']
df_cant_variedad = pd.DataFrame(cant_tot_variedad,index=label_variedad,
columns =['Variedad'])
Os totais de cada classe são transformados em um dataframe, incorporando uma lista de rótulos, conforme detalhado na parte do código com a variável 'label_variedade' (variedad em espanhol).
Fase de carregamento (loading)
Nesta fase, os dataframes gerados na fase de transformação são carregados nas coleções do MongoDB.
setosa_coll = json.loads(setosa_data.T.to_json()).values()
db.setosa.insert(setosa_coll)
versicolor_coll = json.loads(versicolor_data.T.to_json()).values()
db.versicolor.insert(versicolor_coll)
virginica_coll = json.loads(virginica_data.T.to_json()).values()
db.virginica.insert(virginica_coll)
cant_variedad_coll = json.loads(df_cant_variedad.to_json()).values()
db.cant_variedad.insert(cant_variedad_coll)
Verifique se as coleções foram salvas no MongoDB e se o banco de dados foi criado:
test> show dbs
db_iris 32.00 KiB
E as coleções:
test> use db_iris
switched tcollectionso db db_iris
db_iris> show collections
cant_variedad
setosa
versicolor
virginica
É exibido que há um total de quatro coleções, sendo três referentes às classes e cant_variedade, que se refere ao total de registros de cada classe. Para consultar o conteúdo de uma coleção, aplique:
dbiris> db.cantvariedad.find();
[
{
id: ObjectId("63ad39af34e57403210047b9"),
Setosa: 50,
Versicolor: 50,
Virginica: 50
}
]
Visualização de dados
Crie um arquivo Python no diretório principal:
touch dashboard.py
Importação de dados desde o MongoDB
Importe as bibliotecas Pymongo e Pandas para acessar e operar os dados, respectivamente.
import pandas as pd
from pymongo import MongoClient
Conexão com o MongoDB para extrair os dataframes de suas coleções.
mongClient = MongoClient('127.0.0.1', 27017)
db = mongClient.db_iris
setosa_df = pd.DataFrame(list(db.setosa.find()))
versicolor_df = pd.DataFrame(list(db.versicolor.find()))
virginica_df = pd.DataFrame(list(db.virginica.find()))
cant_variedad_df = pd.DataFrame(list(db.cant_variedad.find()))
Teste no Jupyter Notebook que extraiu os documentos do MongoDB com alguma variável:
_id Setosa Versicolor Virginica
0 63b0e2ff029958f05d92ce23 50 50 50
Criação do Dashboard
Importar bibliotecas:
from dash import Dash, html, dcc, Input, Output, dash_table
import dash_bootstrap_components as dbc
Descrição das bibliotecas importadas
Dash: A biblioteca Dash permite implantação em Flask; Seu componente mais utilizado é o layout, onde estão alojados os componentes Html, CSS e JavaScript.
Html: É o módulo para criação de componentes Html, como div, body, p, a, entre outros.
Dcc: É o módulo Dash Core Components, dá acesso a componentes interativos como dropbox, sliders, radio button, entre outros.
Input: contém os componentes de entrada de um método callback que são aplicados a um Dcc.
Output: Contém os componentes de saída de um método callback que são aplicados a um Dcc.
Dash_table: É o módulo que permite criar tabelas de dados. Seu comportamento é personalizável através de suas propriedades, as tabelas de dados são renderizadas.
Dbc: É uma biblioteca de componentes bootstrap no Dash framework, que facilita a criação de aplicativos adicionando capacidade de resposta.
Criação da barra de navegação
logo = 'https://i.pinimg.com/originals/a3/66/f0/a366f0985b6d2750b0242b66fbdef604.png'
navbar = dbc.NavbarSimple(
brand='Iris Dashboard',
brandstyle={'fontSize': 40, 'color': 'white'},
children=
[
html.A(
html.Img(src=logo, width='100',height='40'),
href='https://archive.ics.uci.edu/ml/datasets/iris',
target='_blank',
style={'color': 'black'}
)
],
color='primary',
fluid=True,
sticky='top'
)
O link do logotipo é uma imagem aberta. A biblioteca dbc chama seu componente NavbarSimple para criar uma barra de navegação simples, personalizando cor, tamanho da fonte e seus componentes filhos. Como visto na imagem.

Deployment
Para implantar o aplicativo, a variável app do componente Dash é executada com seu método run_server.
app = Dash(external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = html.Div([navbar,])
if name == 'main':
app.run_server(debug=True)
Para adicionar responsive ao aplicativo, o tema BOOTSTRAP é adicionado por meio de seu componente dbc.BOOTSTRAP. A execução do arquivo Python deve mostrar o seguinte:
(venv) kleber@legion:~/dashboard_open$ python dashboard.py
Dash is running on http://127.0.0.1:8050/
* Serving Flask app 'dashboard'
* Debug mode: on
O aplicativo está sendo executado localmente:
- Host: 127.0.0.1
- Porto: 8050
- Servidor: Flask
O aplicativo seria exibido no navegador:

Componentes no Dash
Bolo de totais
Para adicionar o gráfico de bolo no Dash, importamos o componente graph_objects da biblioteca Plotly.
import plotly.graph_objects as go
pie_variedad_totales = go.Figure(
data= [
go.Pie(labels=cant_variedad_df.T.index[1:4].tolist(),
values=cant_variedad_df.T[0].values[1:4].tolist())
],
layout= {
"title": "Variedad Iris",
"height": 390, # px
"width": 390,
},
)
O componente graph_object é então usado para criar um gráfico de bolo, conforme indicado no código. O componente, além de utilizar o label e os values, que são os dados do dataframe, adiciona propriedades do gráfico como título, altura e largura. Para apresentar o gráfico, você deve criar um componente dcc.Graph, que é um componente do tipo gráfico. Finalmente, adicione o objeto gráfico pie_variedad_totales:
app.layout = html.Div([
navbar,
dcc.Graph(
id='Exports-vs-products',
figure=pie_variedad_totales
)
])
A saída no Dashboard:

Tabela e gráfico linear dos dataframes
Nesta seção final, uma tabela será mostrada usando um método de callback, para alterar as informações das diferentes variedades da planta íris. Um componente dropdown é criado para escolher o tipo de variedade:
drop_vary=dcc.Dropdown(id='drop_vary',options=cant_variedad_df.T.index[1:4].tolist())

Por fim, uma tabela é criada em conjunto com seu gráfico para representar os dados de cada uma das classes de variedade no conjunto de dados da íris.
Comando para criar a tabela:
dash_table.DataTable(id='data-iris'),
Comando para criar o gráfico de dados:
dcc.Graph(id='graph-iris')
A tabela e o gráfico são componentes que são atualizados de acordo com a seleção do usuário no menu dropdown. As opções são classes de variedades como setosa, versicolor e virginica.
Para atualizar a tabela, aplique o seguinte:
@app.callback(
Output('data-iris', 'data'),
Input('drop_vary', 'value'),
)
def update_table(drop_vary):
if drop_vary=='setosa':
ta_re=setosa_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
elif drop_vary=='Versicolor':
ta_re=versicolor_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
elif drop_vary=='Virginica':
ta_re=virginica_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
else:
ta_re=setosa_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
return ta_re
O decorator app.callback é chamado para atualizar os campos. O elemento de entrada drop_vary permite que você escolha a classe de variedade de íris. A saída é a tabela data-iris, que é atualizada com base na classe de variedade. A função de atualização update_table recebe o id drop_vary do componente dropdown.
Por meio de ifs aninhados, o quadro de dados é escolhido para exibir os dados na variável ta_re. Por fim, a propriedade data é retornada, atualizando a tabela de dados.
Atualizar o gráfico
@app.callback(
Output('graph-iris', 'figure'),
Input('drop_vary', 'value'),
)
def update_chart(drop_vary):
if drop_vary=='setosa':
fig_len= px.scatter(setosa_df, x="sepal.length", y="petal.length")
elif drop_vary=='Versicolor':
fig_len= px.scatter(versicolor_df, x="sepal.length", y="petal.length")
elif drop_vary=='Virginica':
fig_len= px.scatter(virginica_df, x="sepal.length", y="petal.length")
else:
fig_len= px.scatter(setosa_df, x="sepal.length", y="petal.length")
return fig_len
Como na tabela, o decorator é chamado para indicar a entrada e a saída dos componentes. Em conjunto com a função de atualização update_chart, você escolhe os dados do gráfico a serem retornados na variável graph-iris. A saída do código:
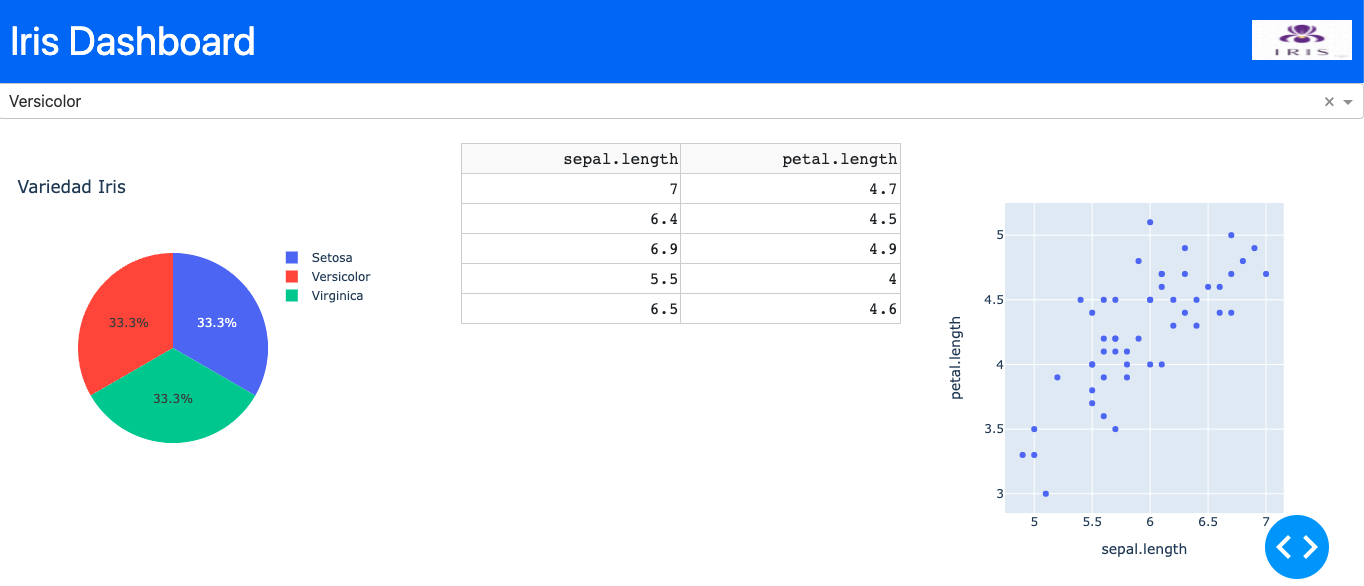
No gráfico foi escolhida a classe da variedade versicolor, mostrando na tabela o comprimento da sépala e da pétala, de um lado o gráfico com o total de pontos. A tabela mostra apenas os 5 primeiros dados.
Concluo que com este livro de receitas você pode começar a fazer Dashboard usando ferramentas absolutamente Open Source.
Recomendo que siga os canais oficiais das ferramentas como https://dash.plotly.com/ e https://www.mongodb.com/try/download/shell.
Você pode clonar o código completo do repositório GitHub do meu perfil.
Em breve publicarei mais conteúdo sobre Data Science. Siga-me para mais conteúdos semelhantes.
Até logo!
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.